
Hello, I’m Duc, responsible for the optimization of our press release access logging system. I’m excited to share the transformative journey we embarked on, moving from a traditional log system that recorded every access in our database to a more streamlined and effective approach.
Background
Let’s begin by examining the challenges we encountered with our previous logging system. Initially, it was a basic setup: each view of a press release page triggered the addition of a new record to our logging table.

This approach, while straightforward initially, became increasingly problematic as the volume of requests to our web servers escalated. The system was overwhelmed by the sheer number of individual records, making the retrieval and manipulation of this vast data both complex and costly. Moreover, the system’s design, focused solely on logging each request, lacked the capability to discern and filter out untrustworthy accesses, such as bot or hacking attempts. This limitation not only added to the data bloat but also posed a significant vulnerability, undermining our data analysis efforts and further exacerbating the challenges, thereby underscoring the need for a more efficient, cost-effective, and secure logging solution.
Integrating Fastly, Amazon S3, and Lambda for Enhanced Access Log Aggregation
We’ve embarked on a transformative journey, developing an entirely new architecture to address the limitations of our previous system.
Leveraging Fastly and Amazon S3 for efficient access log aggregation
Our journey began with the infrastructure team’s initiative to transition our CDN from AWS CloudFront to Fastly. This move was strategic, timed to coincide with the revamp of our logging system.

Based on the design, Fastly logs will be stored in Amazon S3 every 5 minutes. This storage frequency allows us to efficiently capture and analyse the data, enabling us to gain valuable insights into the number of accesses on the press release detail page. By leveraging each new set of data stored in S3 from the previous 5 minutes, we can accurately track and measure user engagement, helping us make informed decisions and optimise our strategies for maximum impact.
Consider the contrast in data logging between our old and new systems:
Old System – Individual Record Logging:
| company_id | release_id | remote_addr | access_date | access_id | is_unique |
|---|---|---|---|---|---|
| 999999 | 1 | 192.0.2.1 | 2023-07-20 16:05:40 | 7294000714 | true |
| 888888 | 1 | 192.0.2.2 | 2023-07-20 16:05:42 | 7294000715 | false |
| 999999 | 1 | 192.0.2.2 | 2023-07-20 16:05:50 | 7294000716 | true |
| 999999 | 3 | 192.0.2.1 | 2023-07-20 16:06:30 | 7294000717 | true |
| 999999 | 3 | 192.0.2.1 | 2023-07-20 16:06:40 | 7294000718 | false |
| 999999 | 1 | 192.0.2.4 | 2023-07-20 16:09:40 | 7294000719 | true |
New System – Aggregated Access Logging:
| company_id | release_id | page_views | unique_user_count | target_access_at | created_at |
|---|---|---|---|---|---|
| 999999 | 1 | 3 | 3 | 2023-07-20 16:05:50 | 2023-07-20 16:10:10 |
| 999999 | 3 | 2 | 1 | 2023-07-20 16:06:40 | 2023-07-20 16:10:12 |
| 888888 | 1 | 1 | 0 | 2023-07-20 16:05:42 | 2023-07-20 16:10:10 |
This shift from individual to aggregated logs not only enhances data management but also paves the way for more advanced analytics.
Adapting and Evolving: Navigating Legacy Systems with EventBridge and Lambda
In the process of upgrading our logging system, we encountered the intricate task of integrating existing functionalities, particularly within our Ranking and Analysis Systems, which were deeply interwoven with the old system. Mindful of these dependencies, we carefully developed two bespoke access log aggregation mechanisms. Each was thoughtfully tailored to meet the unique requirements of its respective system without causing disruption.
Progressing in this journey, we recognised the need for enhanced scalability and robustness in our architecture. To address this, we modestly integrated AWS EventBridge and Lambda into our workflow. This step, while significant, is just one part of our continuous effort to strengthen and scale our systems in response to evolving needs.
Every export of Fastly’s access logs to Amazon S3 initiates a multipart upload event, which in turn triggers AWS EventBridge. This chain reaction then sets off Lambda functions, each designed for various applications. This aspect of our system is a modest reflection of our dedication to a logging system that is dynamic, responsive, and ever-improving.

With an eye towards future possibilities, we are gently exploring ways to expand the use of our CDN log data. Our aim is to extend the reach of our logging capabilities beyond just monitoring press release page visits, to encompass a broader spectrum of data within the PR TIMES domain. This forward-thinking approach is driven by our commitment to not just adapt to current requirements but to anticipate and prepare for future challenges. Our new architecture, while still evolving, marks a small step towards ensuring that we remain agile and responsive to diverse data needs.
Revamping Analytic and Ranking Systems
Following our new architecture, we have deployed two specialised Lambda functions to process access log data. These functions are instrumental in creating a refined data source, serving as the foundation for our overhauled Ranking and Analytics Systems.
Ranking System Implementation
When using the term “Ranking System” it refers to a set of features responsible for generating a ranking board of press releases based on certain ranking criteria. One of the most easily visible functions is the ranking boards displayed at the top of the PR TIMES homepage.

Previously, this system was challenged by data inconsistency and resource intensity due to a fragmented storage approach. We have been trying to increase the number of ranking boards we could generate. However, we faced performance issues that made it difficult to expand beyond our existing capacity. The system was struggling to handle the increased load, which limited our ability to offer a broader range of rankings
Dealing with Deadlocks in Lambda Functions
Implementing Lambda functions for our Ranking System presented unique challenges due to their inherent parallel processing. Our access log data, divided across numerous files, each activates a separate Lambda function. This approach increased the risk of deadlocks, particularly because our log table uses a composite primary key combining release_id, company_id, and access_timestamp.
Occasionally, data entries with identical primary key values emerged, necessitating an aggregation process to maintain data integrity. However, this aggregation, combined with Lambda functions’ parallelism, amplified the risk of deadlocks.
Furthermore, to optimise performance, we adopted a bulk insert strategy for data transfer into PostgreSQL. While efficient, this method introduces its own set of challenges, notably the risk of deadlocks during concurrent insert operations.
This Go function snippet below demonstrates our approach to detecting deadlocks in PostgreSQL, where error code 40P01 indicates a deadlock scenario.
import "github.com/lib/pq" // postgresql driver
...
func detectPostgresDeadlock(err error) bool {
var pqErr *pq.Error
if errors.As(err, &pqErr) {
// Handle the error.
switch pqErr.Code {
case "40P01":
return true
}
}
return false
}In response, we carefully crafted an error-handling mechanism tailored for PostgreSQL. When a deadlock is detected, our system thoughtfully initiates a retry procedure. This process, designed to mitigate the chances of recurrent deadlocks, includes strategies like exponential backoff and a maximum retry limit. We hope that this approach ensures smoother data processing and maintains the integrity of our ranking data.
Centralising Ranking System Architecture
Originally, our Ranking System was configured with a decentralized model, primarily to facilitate quick data access, akin to caching. We had three web servers, each independently running the same ranking calculation logic. The ranking data, critical for swift access, was stored in unique, proprietary DAT files locally on these servers.
This design choice, while effective in ensuring rapid data retrieval, led to a significant challenge: inconsistency in ranking data. Since each server operated separately and stored its own set of these distinct DAT files, discrepancies emerged between them. These inconsistencies, coupled with the resource-intensive nature of maintaining multiple data sets, presented a substantial hurdle in our pursuit of a reliable and unified ranking system.

To address these issues, we decided to move away from the decentralized model. We centralized the ranking data generation and storage to a single server. This strategic shift was aimed at harmonizing the ranking data across the system, thereby eliminating the inconsistencies that plagued our previous setup.
In making this transition, we were mindful of the need to maintain the quick data access that the original system provided. Therefore, we implemented robust data processing and retrieval strategies on the central server. These strategies were designed to replicate the speed of the decentralized system while significantly improving data consistency and reducing the operational burden of managing multiple data sets.
Enhancing Ranking Calculation Logic
Additionally, our previous ranking calculation logic had its vulnerabilities, making it relatively easy to manipulate for a high position on the leaderboard.
To counter this, we’ve implemented detection logic that strengthens our measurement log mechanisms. As a result, exploiting our ranking system for an artificially high position has become considerably more challenging.
These revisions aim to provide a more reliable and resource-efficient system that fairly represents rankings while mitigating vulnerabilities.
Streamlining our data storage mechanism of Analytic Systems
Our Analytics Systems play an integral role in providing insights into press release access logs. Recognizing areas for improvement, we embarked on a journey of modest yet impactful enhancements.

Implementing Advisory Locks for Idempotence in AWS Lambda
In contrast to the enhancements in our Ranking System, the Analytics Systems at PR TIMES demand an even higher degree of data accuracy, a critical aspect of our service offering. One of the key challenges we faced in this regard was the inherent nature of AWS Lambda functions not being idempotent.
This characteristic posed a significant hurdle, as our Analytics Systems rely on delivering the most precise data to our clients.
Initially, we considered using SELECT FOR UPDATE to address this issue. This approach, however, proved challenging, particularly when two transactions began but had not yet committed. In such scenarios, SELECT FOR UPDATE was not feasible for records that did not exist yet. Furthermore, we had concerns about performance impacts and the potential for deadlocks, leading us to rule out using the ‘repeatable read’ isolation level.
To navigate these complexities, we turned to advisory locks as a more flexible and efficient alternative. Unlike traditional database locks that operate at the table or row level, advisory locks offer application-defined locking mechanisms. This unique approach allows us to lock a specific identifier, as determined by our own application, instead of locking database elements directly.
By applying an advisory lock uniquely named after the corresponding S3 file it intends to lock, we ensure that if multiple operations target the same file, the advisory lock prevents data duplication. This method has been instrumental in preserving the highest level of data accuracy in our analytics, achieving idempotence even in situations where the targeted record does not exist in the database.

This implementation of advisory locks in our AWS Lambda functions demonstrates our commitment to maintaining the utmost data integrity. By ensuring that each operation is unique and non-repetitive, we provide our clients with the assurance that the analytics they receive are not only swift and responsive but also precisely accurate and reliable.
Refinement of Data Processing Algorithms
One area we gently addressed was a previously overlooked flaw in our old system, specifically in calculating the unique user count. This metric is crucial for our clients in assessing the reach and impact of their press releases, but our earlier system’s methodology occasionally led to inaccuracies in these counts. We recognized the importance of this issue and took modest steps to correct it.
These modest improvements in our algorithms, though small, underscore our commitment to providing precise and trustworthy analytics to our clients.
Final Result
Refactoring Legacy Code for Ongoing Improvement
In line with our commitment to continuous improvement, we’ve taken steps to revisit and refactor our existing legacy codebase.
This careful process has been instructive for us. It’s allowed us to make some enhancements in system performance and maintainability, while also giving us the opportunity to address foundational requirements more adequately.We’re hopeful that these changes, though incremental, will contribute to a more stable and efficient system, better equipped to adapt to the needs of our users as they evolve.
Optimized Analysis Performance
In managing our Analytics System at PR TIMES, we faced the substantial task of processing an immense volume of data, characterized by the ‘one access per record’ approach. This presented a considerable challenge in maintaining efficiency.
With careful and thoughtful efforts, we have made significant strides in reducing the data processing time. Our team diligently focused on refining the system’s ability to handle the large number of individual access records more efficiently. These improvements, though achieved through modest means, have resulted in a more responsive and capable analytics system.
While these enhancements may seem incremental, they are pivotal in our ongoing endeavor to provide reliable and effective analytics services. We are hopeful that these modest improvements will aid our clients in deriving more value from their data, reinforcing our commitment to continuous improvement and client satisfaction.
Expanded Ranking boards from 5 to 55
Our old ranking system could only produce overall scores for all categories of press releases. We’ve always wanted to create special rankings for different types of press releases, but we were held back by our database’s limits.
Now, we’ve managed to get past these problems. These improvements have allowed us to start using more detailed ranking methods. We’ve moved from just having five types of rankings to offering 55. This change has solved earlier issues we had with system performance. This means our ranking system is now better and can handle a wider variety of press releases, giving more specific and useful results.
Reducing System Load
Revising our logging strategy to consolidate the CDN’s access logs into the database yielded significant results. While seemingly minor on the surface, this shift held considerable potential. It led to fewer insert transactions, lightening the database’s load and bolstering its capacity to handle other tasks, which in turn, enhanced overall system efficiency.

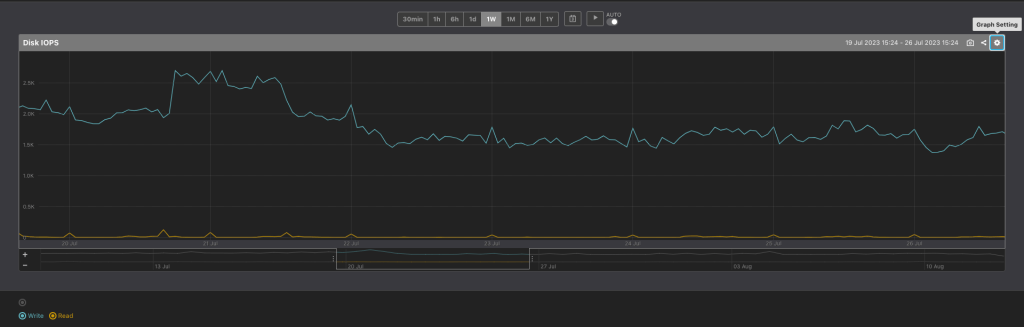
Moreover, resources were optimally utilised, setting the stage for future scalability. Streamlined processing of access logs removed potential bottlenecks, making our system more robust. This evolved approach prepares us for effortlessly handling greater volumes of data, without any detriment to system performance or efficiency.
Conclusion
In conclusion, with the new approach, we successfully overcame the most daunting challenge of database overload, reducing the stress on the system while increasing its efficiency and maintaining accuracy. The new architecture not only made our system more scalable but also resilient, as it stands prepared for future demands and data needs. Our tinkering did not stop at this. Altering the storage mechanism for our Analytic Systems and refining our Ranking System has shown remarkable results in performance boost, data consistency, security enhancement, and code readability.







