
こんにちは、インフラチームテックリードの櫻井です。
今回はFluentdプラグインの暴走によってサーバーのストレージが枯渇しかけた話について紹介したいと思います。
アラート通知は突然に
とある土曜日の夕方ごろ、1件のアラート通知がスマホに届きました。
“Filesystem % 90.19% > 90%”
どうやら本番環境のバッチサーバーのストレージ使用率が90%を超えてしまったようです。
直近のストレージ使用量の推移を見てみると、朝の10時ごろからものすごいペースで増え続けており、あと30分ほどでストレージが枯渇してしまうという状況でした。
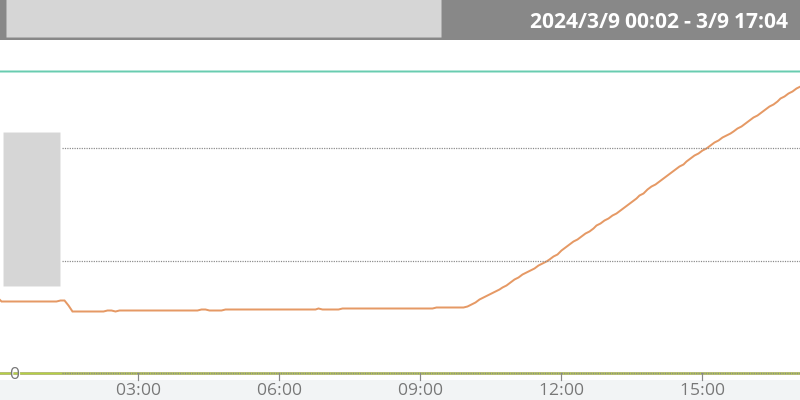
あいにく私は当時私用で外出中だったため手元にPCがなく、Slackで他のメンバーに助けを求めました。
するとちょうどPHPerKaigi 2024に参加中だったCTOの金子がこれに気づき、原因となっていたログファイルの削除などの対応をすることで、なんとかストレージの枯渇は回避することができました。
ちなみにPHPerKaigi 2024についてもブログ記事を公開しているので、よければこちらも読んでみてください。


もしこの対応がもっと遅れていたら、本番環境のバッチ処理が全て動かなくなるなど大規模なインシデントにつながっていたということを考えると、まさに間一髪の出来事でした。
原因
原因はFluentdプラグインの無限ループ
ストレージを圧迫していたのはfluentd(td-agent)の出力する td-agent.log ファイルだったことが分かりました。
実際にファイルの中身を見てみると以下のようなメッセージが出力されていました。
[error]: #0 Can't compress record below required maximum packet size and it will be discarded. Record: {"timestamp"=>1709972117983, "attributes"=>{"hostname"=>"**********", "service_name"=>"fluent.error", "entity.guid"=>"**********", "environment"=>"production"}, "message"=>"Can't compress record below required maximum packet size and it will be discarded. Record: {\\"timestamp\\"=>1709972108726, \\"attributes\\"=>{\\"hostname\\"=>\\"**********\\", \\"service_name\\"=>\\"fluent.error\\", \\"entity.guid\\"=>\\"**********\\", \\"environment\\"=>\\"production\\"}, \\"message\\"=>\\"Can't compress record below required maximum packet size and it will be discarded. Record: {\\\\\\"timestamp\\\\\\"=>1709972095943, \\\\\\"attributes\\\\\\"=> ... (後略)弊社ではサーバー内のログをFluentdのoutputプラグインである newrelic-fluentd-output を使ってNew Relic Logsへ転送しています。
このエラーメッセージはそのプラグインの中でGZIP圧縮後のログの1行のサイズが1MBよりも大きいときに発生するエラーログのようでした。

このエラーログには元のログがそのまま含まれているため、元のログよりもさらに長いログが出力されます。
また td-agent.conf の設定で以下のようにFluentd内部のログも全てNew Relic Logsに転送するようにしていたため、このプラグインのエラーログを再び同じプラグインで転送しようとしてさらに長いエラーログが出力され、そのエラーログを転送しようとして…という無限ループに入ってしまっていました。
<match **>
@type newrelic
license_key "**********"
</match>なぜ極端にサイズの大きいログが出力されたのか
New Relicへログを転送する際のプラグインで無限ループが発生したことで td-agent.log が肥大化し、ストレージを圧迫していたことは分かりました。
しかし先ほどのエラーが発生するにはGZIP圧縮後のログの1行のサイズが1MBを超えている必要があります。
普通のログではまず1行のサイズが1MBを超えることはないはずですが、なぜこのようなログが出力されたのでしょうか。
ログを詳しく調べてみると、以下のコマンドでPostfixキューの中身を全て出力した結果がログに出力されていたことが分かりました。
/sbin/postqueue -pこのコマンドは本来はこのようにPostfixキューの中身を全て出力するのではなく、以下のようにcronでPostfixキューの状態を定期的にログに出力して監視するために設定されていました。
* * * * * /path/to/wrapper.sh /sbin/postqueue -p | tail -1 | logger -i -t postqueueこの wrapper.sh はcronを監視するためのラッパースクリプトで、songmu/horenso を使ってコマンドの開始終了日時や標準出力や標準エラー出力などの情報をJSONL形式でファイルに出力していました。
#!/bin/bash
SCRIPT_DIR=$(cd $(dirname $0); pwd)
horenso \\
-r "php $SCRIPT_DIR/reporter.php" \\
-- "$@"<?php
$result = fgets(STDIN);
$filepath = '/var/log/horenso.log';
file_put_contents($filepath, $result . "\\n", FILE_APPEND);
しかしこの wrapper.sh を先頭につけたことにより
/sbin/postqueue -p | tail -1 | logger -i -t postqueueではなく
/sbin/postqueue -pだけが wrapper.sh の対象になり、Postfixキューの中身全てが1行のログに出力されることとなってしまい、その結果先ほどのFluentdプラグインの無限ループが発生しました。
なぜこのタイミングで起きたのか
cronの設定ミスによりPostfixキューの中身が1行のログに出力され、その結果Fluentdのプラグインが無限ループを起こしてtd-agent.logが肥大化していたということが分かりました。
ここで気になるのが、なぜこのタイミングで突然発生したのかということです。
先ほどのpostqueueコマンドをcronに設定したのもFluentdでNew Relic Logsへの転送設定を行ったのもずっと前のことだったのに、なぜ突然発生したのでしょうか?
実は同じタイミングでmaillogにConnectcion timed outエラーが出力されており、AWSのサポートに問い合わせたところAWSのVPC内からインターネットへの通信の一部で障害が発生していたことが分かりました。
これにより一時的に送信できなかったメールがPostfixのキューに蓄積し、その結果 /sbin/postqueue -p コマンドの出力結果が膨大なサイズになったと思われます。
原因のまとめ
つまり今回の問題は
- AWSのVPC内からインターネットへの通信の一部で障害が発生し、Postfixキューに大量のメールが蓄積していた
- cronの設定ミスによりPostfixキューの中身がすべて1行のログに出力されるようになっていた
- newrelic-fluentd-output プラグインでログ1行のサイズが非常に大きい場合に無限ループが発生するようになっていた
という複数の事象が重なって起こったということが分かりました。
再発防止策
CRITICALアラートの通知のしきい値を変更
今回、ストレージが90%を超えたタイミングでMackerelからSlackにメンションつきのCRITICALアラートが通知されたことで検知することができましたが、もし気づくのが遅れたり対応が遅れた場合に間に合わなくなる可能性があります。
CRITICALアラートのしきい値を90%から50%に変更し、より早いタイミングでSlackにメンションつきのアラートが通知されるようにしました。
cronの設定を修正
まず先ほどのcron設定から /path/to/wrapper.sh を削除し、 Postfixキューの中身がそのままログに出力されることがないようにしました。
* * * * * /sbin/postqueue -p | tail -1 | logger -i -t postqueuenewrelic-fluentd-output プラグインのバージョンアップ
今回の件についてNew Relicのサポートに問い合わせを行ったところ、問い合わせの2日後に無限ループを修正したv1.2.3がリリースされたと共有いただいたので、v1.2.2からv1.2.3へバージョンアップを行いました。
この対応のスピード感は我々も見習いたいと思いましたし、サポートへの問い合わせやフィードバックはもっと積極的にしていくべきだなと思いました。
Fluentd自身のログをNew Relic Logsへ転送しない
先ほどのバージョンアップで今回発生した無限ループの対策はできましたが、まだ問題が残されている可能性があるのと、もしFluentdに問題が発生した場合にFluentd自身のログを転送することができずエラーを検知できない可能性があります。
そのため td-agent.conf を変更してFluentd自身のログはNew Relic Logsに転送しないようにするとともに、Mackrelを使ってtd-agent.logとtd-agentのプロセスを監視するように変更しました。
まずtd-agent.confは以下のように変更し、fluent.error やfluent.info のようなタグが付与されるfluent自身のログをNew Relic Logsへ転送しないようにしました。
<match prtimes.**>
@type newrelic
license_key "**********"
</match>Mackerelを使って td-agent.log 内のエラーログを監視する
次にMackerelを使って td-agent.log 内のエラーログを監視します。
Mackerelでログを監視する場合は公式プラグインの check-log プラグイン を使用します。
mackerel-agent.conf に以下の設定を追記することで /var/log/td-agent/td-agent.log に [error]: を含むログが出力されたときにMackerelへ通知することができます。
[plugin.checks.check_td-agent_log]
command = [
"check-log",
"--file-pattern", "/var/log/td-agent/td-agent.log",
"--pattern", "[error]:",
]Mackerelを使ってtd-agentのプロセスを監視する
次にMackerelを使ってtd-agentのプロセスを監視します。
Mackerelでプロセスを監視する場合は公式プラグインの check-procsプラグイン を使用します。
mackerel-agent.conf に以下の設定を追記することで /opt/td-agent/bin/ruby を含むプロセスが動いていないときにMackerelへ通知することができます。
[plugin.checks.check_td-agent]
command = [
"check-procs",
"--pattern", "/opt/td-agent/bin/ruby"
]mackerel-agent.conf の設定を変更した後はmackerel-agentを再起動することで設定を反映することができます。
$ sudo systemctl restart mackerel-agenttd-agent.log を1時間ごとにローテーションして圧縮する
次に同様の事象が起きたときにストレージの枯渇を防ぐために、td-agent.log を1時間ごとにローテーションして圧縮するようにします。
ログのローテーションにはlogrotateを使っていたため、hourly オプションを追加することで1時間ごとにローテーションさせようとしました。
しかし注意点としてAlma Linux 9などRHEL 9系ではlogrotateがcronではなくsystemd-timerで起動されており、1時間ごとにローテーションさせるためにはlogrotate.timer 内のOnCalendarをdailyからhourly に変更する必要がありました。
詳しくは以下のページに分かりやすくまとまっているのでご参照ください。

まとめ
今回はFluentdプラグインの暴走によってストレージが枯渇しかけた話について紹介しました。
詳しく調査してみるとAWSのネットワーク障害やcronの設定ミスなど複数の要因が重なって起きた問題だったと分かり、とても学びになりました。
今回は大きなインシデントになる直前に回避することができましたが、今後もより早く検知し対応できるように監視を強化していきたいと思います。







