
こんにちは、2021年の頭にPR TIMES に入社し、バックエンドエンジニアをしているベトナム国籍メンバーのズンです。
以前は主にPHP言語で開発をしていますが、入社してから様々なことを勉強になりました。その中でAWSは学んだことの1つです。
現在、PR TIMESではSalesforceが社内業務の一部に利用されています。社内の人間が手動で対応している業務が多くありましたが、ご利用企業が増加してきたため、手数がかかってきました。または、社内で情報が分散してしまっているのを集約することで、よりよい顧客サポートやステークホルダー(PR TIMESに関わる方々)との関係構築を行っていく必要もあります。これに対応して、最新の登録した企業の情報や配信したプレスリリースなど、PR TIMESのデータベース上の一部のデータをSalesforceに自動でインポートされるアプリケーションを作成しました。この記事で勉強になったことを紹介いたします。
設計
Salesforce連携のためにSalesforceの方が様々なAPIが提供しています。提供されているAPIリストはSalesforceの公式ドキュメントサイトで閲覧することができます。
データレコード数は数千件あり、一つずつ更新することは負荷がかかる可能性があるので、データがCSV形式に変換されて、Salesforce REST-based Bulk API 2.0を使って、Bulk Data Load Jobsを登録して、Salesforceにデータ更新処理を任せます。
アプリケーションのフローは以下の図でまとめます。
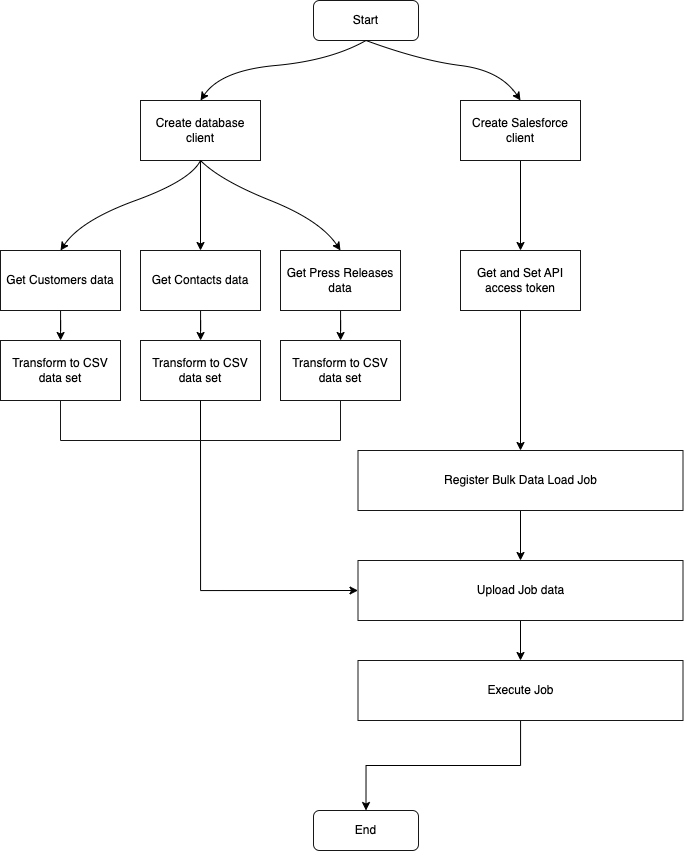
Go言語を使ってアプリケーション作成
以前は主にPHP言語を使っていました。ですが、今回のアプリケーションはAWS Lambdaにデプロイする予定があり、社内だとAWS LambdaとGoの採用事例が多いので、Goを使おうと思いました。大学時代にC言語でプログラミングしたことがあるので、Goに早く慣れました。
色々実装しましたが、自分にとって面白い勉強になった事をまとめます。
データベースの扱い
PostgreSQLデータベースからデータを取得するためにgithub.com/lib/pqとgithub.com/jmoiron/sqlxパッケージを使いました。github.com/lib/pqパッケージはPostgreSQLデータベース用のデータベース ドライバです。Go自体は標準パッケージでsqlパッケージが提供していますが、sqlxパッケージは簡単に構造体にDB.Selectメソッドでデータをマッピングできて、とても便利なので、sqlxパッケージを使いました。
// sqlパッケージを使う場合
type Customer struct {
ID int `db:"id"`
Name string `db:"name"`
Email string `db:"email"`
Phone string `db:"phone_number"`
}
query := “SELECT id, name, email, phone_number FROM customers LIMIT 1”
customer := Customer{}
row, err := DB.Query(query)
row.Scan(&customer.Id, &customer.Name, &customer.Email, &customer.Phone)
DB.Close()
// customerのフィールドが増やしたらScanメソッドが大変になる// sqlxパッケージを使う場合
type Customer struct {
ID int `db:"id"`
Name string `db:"name"`
Email string `db:"email"`
Phone string `db:"phone_number"`
}
customer := Customer{}
query := “SELECT id, name, email, phone_number FROM customers LIMIT 1”
DB.Select(&customer, query)
DB.Close()
// customerのフィールドが増やしてもDB.Select関数の引数が変更不要データベース上のnullを取得した場合、Goのゼロ値に初期化されます。intのゼロ値は0、stringのゼロ値は空文字列です。そのためにnullとGoのゼロ値を区別することができません。Goではnilがありますが、ポインタ型しか利用できません。それで
gopkg.in/guregu/null.v4パッケージを使いました。gopkg.in/guregu/null.v4パッケージのnull.Stringやnull.Intなどの構造体はsqlパッケージのsql.NullStringやsql.NullIntなどの構造体と似ていますが、null値に対して様々な便利なメソッドを提供します。
Goのポインタを詳しく理解する
Cと同様に、Goのポインタというのは変数の値が保存されるメモリのアドレスの情報です。
詳しくはGoの公式のドキュメントを参考することができます。
関数やメソッドにポインタ変数を渡すと、変数自体の値を変更することができます。
package main
import "fmt"
func main() {
num := 1
plus1(num)
fmt.Printf("変数を渡す場合: %v\n", num)
plus1ByPointer(&num)
fmt.Printf("ポインタ変数を渡す場合: %v\n", num)
}
func plus1(i int) {
i += 1
}
func plus1ByPointer(i *int) {
*i += 1
}実行結果を見ると、num変数で保存される値が変更されたのが見えます。
変数を渡す場合: 1
ポインタ変数を渡す場合: 2
Program exited.変数自体の値を変更したくない場合も関数やメソッドにポインタ変数を渡した方がいいというベストプラクティスも勉強になりました。理由は、関数やメソッドに変数を渡す時に、データのコピーが生成されて、利用されます。変数の値のサイズが大きければ大きいほど、メモリを使用します。ポインタを利用する場合はデータのコピーが生成されないので、メモリが節約できることがあります。
CSVデータの扱い
Salesforceの登録しておくBulk Data Load Jobsにデータを登録するためにCSVフォーマットでにデータを変換する必要があります。そのためにGoのencoding/csvパッケージを使いました。CSVデータのための文字処理、文字エスケープ、ファイルから読み込み、ファイルに書き込みなどのメソッドを提供します。
最初に私がデータベースから取得したデータをCSVファイルに書き込みして、Bulk Data Load Jobsにデータを登録する関数でCSVファイルからデータを読み込んで、データを登録する方針によって実行しました。もっといい方法があります。
それを避けて、Goのio.Reader、io.Writerインタフェースの使い方を教えていただきました。
各データ型に扱うパッケージ、strings、bytes、encoding/csv、os.FilesなどのパッケージがReaderメソッドとWriterメソッド(I/O)を提供しています。基本的にそれらはio パッケージのReaderとWriterをインプリメントしています。Goでは、基本的に「ioパッケージのインターフェースによって、どこからのI/Oであっても同様に扱える」ということがあります。ですから、具体的な例としては引数としてio.Readerを受け取る関数はstrings.Reader、bytes.Reader、os.Files.Readerなども引数として受け取れます。Writerに対しても同様です。
func (s *Client) UploadCSVData(url, jobID string, reader io.Reader) error {
req, err:= http.NewRequest("PUT", url, reader)
if err != nil {
return err
}
req.Header.Set("Authorization", "Bearer "+s.AccessToken)
req.Header.Set("Content-Type", "text/csv")
req.Header.Set("Accept", "application/json")
resp, err := s.HTTPClient.Do(req)
// response handling
}
// ファイルのReader
fileData := os.open("sampleData.csv")
err := s.UploadCSVData(fileData)
// 文字列のReader
stringData := "sample csv data"
stringReader := strings.NewReader(stringData)
err := s.UploadCSVData(stringReader)
// バイト列のReader
bytesData := []byte("sample csv data")
bytesReader := bytes.NewReader(CSVBytesData)
err := s.UploadCSVData(stringReader)どちらの方法も使えますが、csvデータを保存するために、ファイル作成を避けて、stringsのReaderと Writerを使いました。
もう一つ問題が発生しました。Writerを作成した時にWriter Bufferのサイズが上限があって、全部のデータが保存できなかったです。それでbufio.NewWriterSize()を使って、大きいサイズのWriterを作成しました。
AWS環境へデプロイ
既存のシステムへの影響を最小限にするためにサーバーレスサービスの利点を利用して、インフラストラクチャについてあまり心配することなく、アプリケーションの開発により集中するのために、AWS Lambdaサービスを使おうと決めました。PR TIMESの本番データベースは、2022年9月にAWSへ移行される前に、オンプレミス環境で動かしていて、本番データベースに負荷がかかると問題になっていました。それで、Salesforceにリアルタイムのデータを更新する変わりに、PR TIMES社内で利用されているデータ解析のために毎日本番データベースからEC2インスタンスにレストアされるデータベースからデータを取得するようにしました。現在ではPR TIMESシステムがAWSクラウド環境へ移行したため、AWS RDSにあるリードレプリカのデータベースを参照しています。
自分で考えた仕組みはPR TIMESの方で更新されたデータの直前の1日内の分をSalesforceへ登録することでした。しかし、アプリが稼働する最中にエラーが出てくる場合は、まだ登録されないデータがどうなりますか?ということ悩んでいました。
これについて一番簡単な解決策は、直前の1日だけのデータを取得する代わりに最新の3日間のデータを取得した方がいいです。そうすると、前日にアプリがエラーが発生しても、次の日に登録されなかったデータの分が登録されるようになります。アプリケーション設計は、動けるように設計するのはもちろん、失敗しても影響を小さく与えないようにフォルトトレランスを持つアプリを設計する必要があることを勉強になりました。
上記の仕組みを建築するために以下のAWSサービスを利用することにしました:
- アプリケーションを実行するためにAWS Lambdaを利用する。Amazon RDSにあるデータベースからデータが取得される
- 毎日イベントをトリガーし、AWS Lambdaにある関数を呼び出すためにAmazon EventBridgeを利用する
- Salesforce連携用のシークレットを保存するためにAWS Secrets Managerを利用する
- アプリケーション実行中のログを保存するためにAmazon CloudWatch Logsを利用する
構築としては以下の図でまとめます。

AWS Lambdaの管理コンソール経由で簡単に作成したアプリケーションをデプロイすることもできますが、AWS Lambdaのための開発やデプロイをサポートするLambrollというツールが提案してもらって、Lambrollを利用しました。
詳細はこちらの記事で参考することができます。

AWS Lambda関数を呼び出すためにトリガーを設定する必要があります。AWS自体のサービスも外部のサービスもどちらからもイベントトリガーを設定することができますが、今回にはAWS EventBridgeで毎日8時に関数を実行するトリガーを設定しました。
AWS RDSでのデータベースからデータを取得したり、AWS Secrets Managerで保存されるシークレットを取得したり、AWS CloudWatch Logsにログを保存したりするためにAWS Lambda関数にRDSにアクセス権限のIAM Roleを追加する必要もあります。
まとめ
今回、社内の仕事をサポートするアプリケーションを作成したとともに自分がGoやAWS Lambdaについて様々なことを勉強になりました。サーバーレスサービスはとても便利で、将来にPR TIMESの仕事でもっと活用したいと思います。
PRTIMESで働く間、いつも自分の成長を応援してもらうと感じます。もっと新しい事、難しい事を挑戦したいです。前向きに行きましょう!







