
こんにちは!開発本部のエンジニアのトゥ(codyzard)です。
今回は数ヶ月前にリリースされたプレスキット一括ダウンロードの機能を話したいと思います。
背景
2022年2月にプレスキット機能をリリースしました。興味があれば以下の記事を参考してください。


しかし、それまでのプレスキットでは1つ1つの素材しかダウンロードできませんでした。いくつも欲しい素材があったときにダウンロードに手間と時間がかかります。メディアは記事公開までの時間にシビアなところも多く、プレスキットを活用してもらうには使いたいときにすぐに使えるようにすることが必要になります。なので、欲しい素材を一括でダウンロードできるようにすることで、ダウンロードにかかる手間と時間を減らすことを目指しました。
この記事は、プレスキット一括ダウンロードの機能を構築するために構成はどうなったか、技術は何を使ったか、Lambdaの実行の時に何の問題が起こったかということを話したいと思います。
構成と技術について
構成

上の図のように機能を実装していました。インフラは全部のAWSサービスを使っています。様々なサービスを使っているので、1つ1つ解説していきます。
ステップ1は、プレスキット素材を選択してから、ユーザーはPHPウェブサーバーへリクエストします。PHPウェブサーバーサーバー側はvalidation用のLambdaを通じて、ユーザーが選択したもののバリデーションを完了した上で「zipファイル確認用のキー」を生成します。zipファイルの処理完了を確認するために「zipファイル確認用のキー」はこのシステムで重要な役割を担っているので、覚えておいてください。この後、「zipファイル確認用のキー」をユーザーに返し、「zipファイル確認用のキー」で「処理中」というitemを結果保存用のDynamoDBにJSON形で保存します。目的は、ポーリングする時にまだ処理中であることをユーザーに知らせることです。
これから2つの処理は同期に実行します。

これからステップ2に入って、2つの処理は同期に実行します。
1つ目は、ユーザーは「zipファイルキー確認用」をもらったら、ダウンロードできるかを確認するために数秒ごとに結果確認用のLambdaをポーリングします。
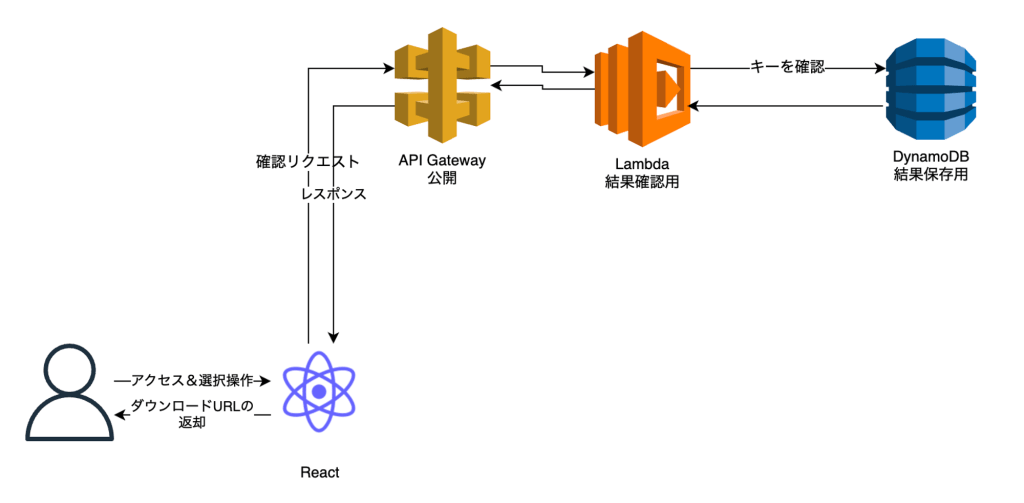
2つ目はzip file用のLambdaは「zipファイル確認用のキー」とS3のオブジェクトキーとファイル名などの付属情報をValidtion用のLambdaからSNSを通じてもらいます。S3のオブジェクトキーとファイル名により、S3からItemをダウンロードした上で全てをzipファイルにします。またzipされたファイルはzipped file & downloadableのS3にアップロードしたあとで「zipファイル確認用のキー」でzipされたファイルのS3 URIと結果保存用のDynamoDBにJSON形で保存されます。

ステップ3は、上に言及したのはPHPウェブサーバーから「zipファイル確認用のキー」をもらってから、結果確認用のLambdaをポーリングしていますね。この時にzipファイルの生成処理が完了したら、ユーザーはそのファイルのS3 URLをもらって、ダウンロード URL から直接、zipファイルをダウンロードできます。

以上に全て説明したのは機能の稼働の順番になります。
技術
技術的にはほとんどAWSサービスを使って、リソースの管理を楽にしたいのでTerraformを運用しました。ただ、Lambrollは簡単にLambdaをデプロイできるツールなので、LambdaのみはTerraformで管理せずにLambrollを使ってみました。
Lambdaの実行で発生した問題
プレスキット機能はGo言語で開発しています。Lambdaの実装は3つありますが、zip fileのLambdaは一番触っていたので良い話だと思うので、それを話します。
構成と技術についての項目のステップ2で言及されたzip fileのLambdaは、「S3からオブジェクトをダウンロードすること」と「それをZip file化すること」を行います。
処理時間を下げることとメモリの管理という問題
まずはS3から全てダウンロードの処理をご覧ください。
func batchDownload(sess *session.Session, bucket string, items [][]structs.BatchDownloadRequestBodyItem) (map[string]string, error) {
tmpFns := make(map[string]string)
for _, v := range items {
for _, item := range v {
// get object key from url
parsedURL, err := url.Parse(item.URI)
objectKey := strings.TrimPrefix(parsedURL.Path, "/")
// download file from s3
tmpFile, err := s3Download(sess, bucket, objectKey)
if err != nil {
return nil, fmt.Errorf("failed to download file: %v", err)
}
defer tmpFile.Close()
tmpFns[item.ID] = tmpFile.Name()
}
}
return tmpFns, nil
}
大体動きそうでしたが、同時にダウンロードするプレスキット素材が多いと時間がかかって、Lambdaのタイムアウトになってしまいます。なので、ダウンロード時間を下げるためにGoroutineを使ってみました。
func batchDownload(sess *session.Session, bucket string, items [][]structs.BatchDownloadRequestBodyItem) (map[string]string, error) {
tmpFns := make(map[string]string)
// semaphore はgoroutineの数量をコントロールする。
semaphore := make(chan struct{}, 10)
// errGrはgoroutine内でエラーが発生した場合にエラーをキャッチするためのグループ
errGr := new(errgroup.Group)
for _, v := range items {
for _, item := range v {
// get object key from url
parsedURL, err := url.Parse(item.URI)
objectKey := strings.TrimPrefix(parsedURL.Path, "/")
if err != nil {
return nil, fmt.Errorf("failed to parse url: %v", err)
}
semaphore <- struct{}{}
id := item.ID
errGr.Go(func() error {
defer func() {
<-semaphore
}()
// download file from s3
tmpFile, err := s3Download(sess, bucket, objectKey)
if err != nil {
return err
}
defer tmpFile.Close()
tmpFns[id] = tmpFile.Name()
return nil
})
}
}
if err := errGr.Wait(); err != nil {
return nil, fmt.Errorf("failed to download file: %v", err)
}
return tmpFns, nil
}
70ファイルぐらいをやってみました。Goroutineを使わなかったら10秒(zip fileの処理時間を含む)になりました。逆にGoroutineを応用すると6.5秒(zip fileの処理時間を含む)に大分下がりました。


処理時間を下げるためにGoroutineで並行に処理をすることが考えられます。しかしGoroutineで全処理を一気に行おうとすれば、メモリもあふれますし、CPUも使い切ってしまいます。そこでchannelを利用して同時実行数を制限する実装を行いました。
semaphore := make(chan struct{}, 10)として、同時に実行できるGoroutineの数を10個に制限しました。当然利用するメモリも増加するため、Lambdaのメモリを少し増やして1024MBを指定しました。
ストレージ管理の問題
処理時間以外はLambdaでストレージ管理することも大事です。なぜかというと、S3からのダウンロード処理もzipファイルの作成もストレージの容量がかなりかかります。Lambdaには再利用という機能があるので、Lambdaの実行が完了した後にストレージ上のファイルを削除しなければディスク容量が無くなってしまいます。ディスク容量が無くなると以下のようなエラーが出てきます。

それを避けるようにzipファイルの処理は終わったらすぐに削除します。
for _, v := range items {
for _, item := range v {
f, err := os.Open(tmpFns[item.ID])
if err != nil {
return nil, fmt.Errorf("can't open file")
}
defer f.Close()
// zipファイルを処理する ...
.
.
.
// remove tmp file after writer into zip file
if err := os.Remove(tmpFns[item.ID]); err != nil {
return nil, fmt.Errorf("can't remove tmp file")
}
}
}それに完全にzipしたファイルはS3にアップロードした後も削除しておきました。
arc, err := archiveFile(sess, body, os.Getenv("PUBLIC_BUCKET"))
// upload zip file
zipFn := body.DLInfo.Filename + "." + body.DLInfo.Extension
result, err := s3UploadBaseOnBucket(sess, os.Getenv("PUBLIC_DOWNLOAD_BUCKET"), arc.Name(), zipFn, body.DLInfo.Key, body.DLInfo.Extension)
// arc(アーカイブファイル) を掃除する
err = os.Remove(arc.Name())
if err != nil {
log.Println(body.DLInfo.Key, err)
}他の問題
上に話した2つの問題の他に、Lambda Concurrencyの注意点にちょっと話したいです。それぞれのアカウントは同期使用可能のLambdaは1000個のみですね。この機能は3個を使用しないといかなくて、たとえ1000ユーザー同期に叩いたら、同期使用リミットに超えてしまって、他のサービスのLambdaに影響を及ぼして、クリティカルヒットになりますので、ちゃんと注意しないといけないです。しかし、今のところ当社規模では心配するアクセスは来ていませんから、Lambda Concurrencyの問題は今のところ気にしていません。
まとめに
今回一括ダウンロードを構築するためにいくつかのAWSサービスをTerraformを初めて活用してました。実際のLambdaの問題にあって、対応できて嬉しいです。
簡単な共有でしたが、この機能の実装を体験したおかげでAWSの知識も補強できて、今年5月にAWS SAAという試験に合格しました。







