
Hello, I’m Duc, currently working on moving our on-premise Elasticsearch server to AWS OpenSearch Service. In this post, I will share how the old Elasticsearch server was replaced by a new one whose core is AWS OpenSearch Service.
Introduction
At the time I’m writing this blog, most of processes that require data from Elasticsearch have been replaced by the new AWS OpenSearch Service. But if we look back over the last few months, PR TIMES’s search engine system was based on Elasticsearch that was manually installed on an on-premise server.
Because of the number of press releases published daily (some even at the same time) at PR TIMES is rapidly growing, the pressure on the old system is gradually overwhelming. The limit is becoming more and more obvious. Along with that, many improvements to Elasticsearch | OpenSearch has been updated since our old Elasticsearch version.
Therefore, we decided it was time for the old system to be retired.

How can we achieve?
There are 3 main problems that we expected to solve by upgrading our search engine:
Inefficient architecture
The old system was designed so that when a release is published or changed, application side enqueue a message to RabbitMQ. After a period of time, a worker will take a look at the queue and get what release has been updated. However, there is a risk in the current RabbitMQ that sometimes the data is going to be too large and eventually die. Which would be terrible because the published or changed release will be NOT indexed in the search engine’s data storage.
Performance and stability issues
We were experiencing a huge number of outages of CPU and load that caused us a lot of headaches. Because of running on premise, it’s will cost us a lot of time, money and resources to solve this proplem. Moving to cloud will remove the hassle of maintaining, updating and scaling the system. Besides, there have been more and more improvements to new OpenSearch engine that we could incorporate to our application.
Poor visibility on our existing cluster
For the old Elasticsearch, when we experienced peaks in load, it took us a lot of time to figure out what was causing it. Therefore, beyond basic metrics like memory, disk, and CPU, we wanted the ability to monitor errors and track under-the-hood metrics like indexing or searching query performance metrics.
Preparation
But how can we do that? What is our plan? Above all, there are some constraints which we must be clear.
Constraints
- Zero downtime migration. We have active users on our system, and we could not afford for the system to be down while we replace the whole system.
- Minimise bugs. We could not change existing search functionality for end-users. Hence, the fewer bugs the better.
Double Write Strategy
There are several ways to reindex data. But in this time, it’s not just purely about data coming out from ES and then loading them into OS.
In addition to simply transferring the data, the management features that read and write these data are also important to consider when we want to roll out a reindex operation.
Another important consideration is the possibility of breaking changes. To avoid any issues, It’s important to ensure that our code is up to date and compatible with the new OpenSearch.
By tackling these considerations, we need a generic rebuild solution that works for all use cases while having no downtime. We decided that the best course of action was to build a new cluster, reindex everything and then switch.
In summary the plan was:
The Plan
- Create new OpenSearch cluster
- Reindex everything
- Periodically reindex new and updated docs
- Test the application using the new cluster
- Switch to new cluster (more on this later)
Here’s how it looks like in real life:


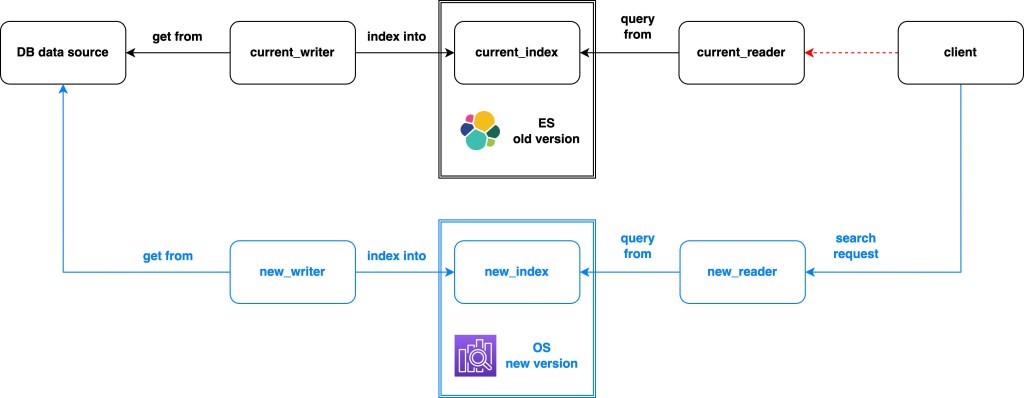
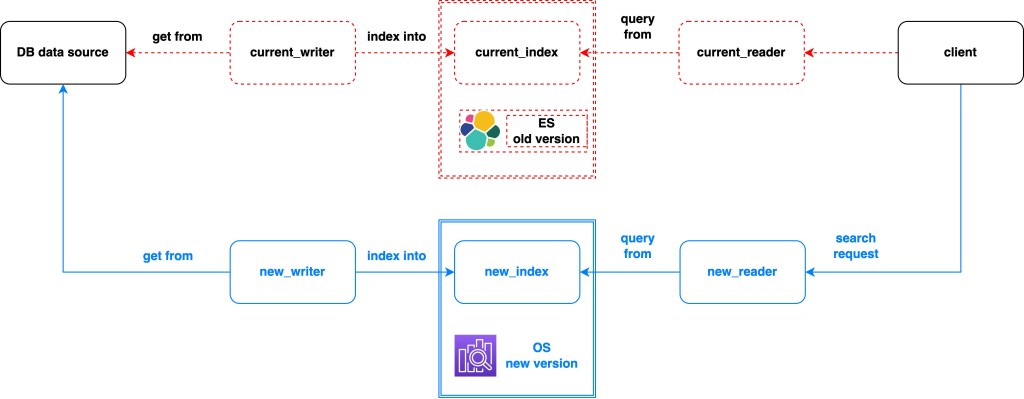
※ Rebuild after Replace (same cluster new index). In case of settings or mapping changes. Depends on situation, we could scale writers or readers up easily.


Minimise bugs
When all the manage-process like rebuilding index and updating documents work perfectly, we will have a cluster full of data which is ready to be used. The next step is to replace the application code so that it can load, transform, and return data from OS to the front-end in pre-defined JSON format.
First of all, the legacy application code is likely to contain dead code. So as well as clinging the current code, we used New Relic to investigate which parts are still in use and which are no longer. Features that are still in use will be replaced with new features that get data from OpenSearch. And the rest, which are no longer in use, will be sent to the graveyard.
After a feature’s application code is prepared to switch to OpenSearch, to minimise risk and increase user engagement, it would take some step before the feature is completely replaced by OpenSearch:
- Use a features flag to allow internal VPN IPs to test the new feature on the production environment.
- If all seems good, the next step is to do AB testing by branching 10-20% of requests volume to the new cluster.
- After few weeks of AB testing, completely move to the new cluster
In addition, monitoring tools should be set up to be able to observe necessary metrics for unusual circumstances.
Execution
To execution the plan, there are some prerequisites we must handle:
- A data source that supports self-consistent and multiple data readers and writers. Because it requires having multiple independent writers/indexers that index the same data into different indices in possibly different clusters.
- Independent between readers and writers. Because it allows us to isolate their deployment, scale and upgrade them independently. In our case, query application and index management code should be created completely new instead of reusing rusty PHP query reader and Ruby writer.
- All data that needs to be indexed must be guaranteed. Because of data consistency – old and new indices must have the same data. This leads to the need for a failure retry mechanism. In case human hands are needed, an error monitor must be prepared.
If we break it down, the goal will be:
Goals
- Replace RabbitMQ with another queue mechanism. The old RabbitMQ system suffers from some inconveniences, so using a log mechanism that saves to a database seems more reasonable.
- Re-establish worker server’s tasks to batch server. Unmaintained Ruby codebase worker server needs to be re-establish to the batch server.
- Refactor and replace legacy application code to be able to integrate with the new OpenSearch.
- Replace ElasticSearch server by AWS OpenSearch Service. Along with the motivation to switch from on-premise to AWS in PR TIMES in recent days. AWS OpenSearch Service seem like a best option for a managed service.
No-Goal
- Upgrading on old ElasticSearch version is unnecessary. Fortunately, all our press releases data is stored in the PostgreSQL, so we are not afraid to lose or corrupt data. In another words, we don’t have to directly migration data from Elasticsearch to OpenSearch, which has a huge version gap. All we need is to replace the current Elasticsearch server and then ingest data directly, safe and sound.
At that moment, our service uses the following architecture:

This is what we are willing to replace:

There are three main processes:
Update process:
- When a press release is about to be published, or a published press release is modified, a message will be enqueued to RabbitMQ.
- The watcher – a process of the worker – periodically checks and dequeues messages from RabbitMQ.
- From the message, the worker gets the press releases that have been changed, loads data from the database, transforms it to a document that satisfies the predefined schema, and then indexes it to the current index.
Rebuild process:
- The worker gets all published release IDs from the database and enqueues them into RabbitMQ.
- The same watcher of the update process continues to check and dequeue messages from RabbitMQ.
- Same as the update process. From the message, the worker loads, transforms, and then loads documents to the new index.
※As a temporary solution for RabbitMQ’s data loss risk, the rebuild process has been set to rebuild the index every day.
Query process:
- Web server send a request to Elasticsearch
- Elasticsearch return data to web server
- Web server transform data and return to front-end under JSON format
The Queue
As mentioned above, the rebuild process is running daily. However, the more data the system has, the longer and heavier the load it takes to rebuild the index.
Additionally, because of using queue, when the system rebuilds a new index, the worker server has to enqueue all data that needs to be indexed to RabbitMQ. Consequently, if a press release is changed or published during the rebuild process, the message will have to wait until the rebuild is completed in order to reach end-user’s hand.
By using a WAL-like mechanism, we can ensure the persistence of state across multiple processing steps for tasks that require it.
The queue architecture:
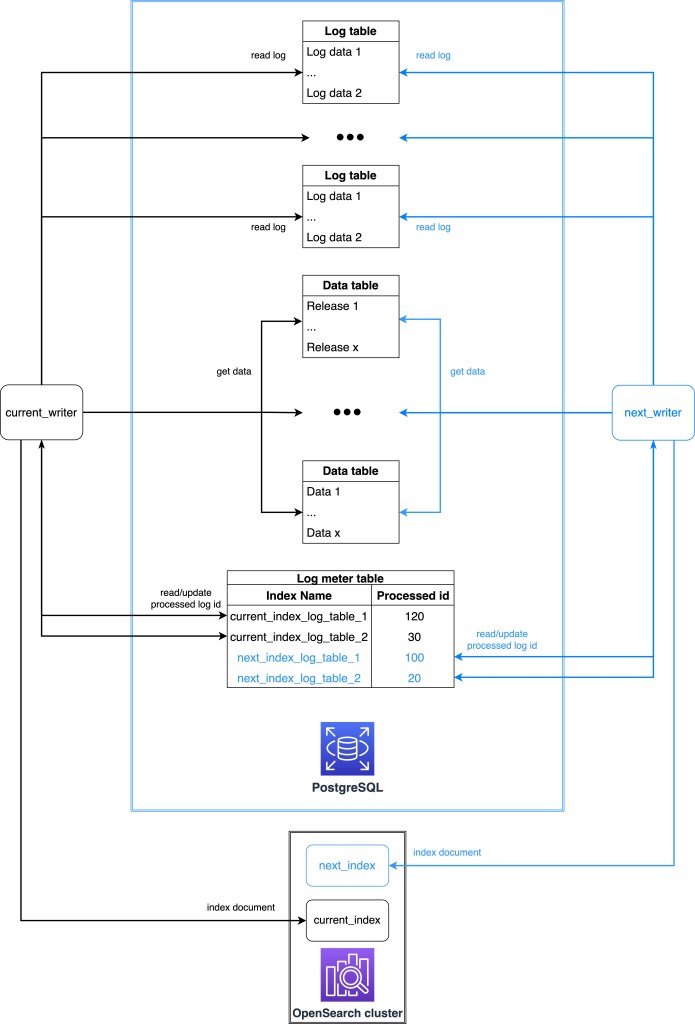
About the logging mechanism, at the beginning, we tried using PostgreSQL’s trigger feature. The simple idea was that every time a change occurred in the database, it would be logged in a dedicated log table. However, we ran into some problems.
- Firstly, and also the main problem, PR TIMES provides a draft mechanism for the editor feature. Draft press releases are archived to the database once a minute. Therefore, if we use triggers, the amount of insert statement volume would be extremely huge, which could lead to an overhead incident on the database. Furthermore, the data stored in the search engine’s data storage only needs published press releases.
- Secondly, the data needed to be collected from more than 10 tables to be transformed into a document and loaded to the search engine’s data storage. But there are cases where tables have relationships with each other. If we just attached a trigger to each table, there would be duplicated data. If we set the trigger elaborately, maintaining them would be a challenge in the future.
As a solution, a code-based event was created. By attach this event to those features that only have responsibility to publish releases or edit|remove published, the log will be saved as we want.
- Otherwise, log table volume will become huge and huge through time. This would affect database performance, and even lead to a critical risk.
Indexes were used, and thankfully in the middle of the journey of this project, we were able to update PostgreSQL version from 9.6 to the new version. As partition features have been released in PostgreSQL version 11, we were able to use them as a timely solution! (btw, we’ll soon be moving from 11 to 14!)

Code base
Re-establish worker server’s tasks to batch server
Find out, refactoring code base is not just a coup d’état, it’s totally a revolution.
Due to lack of manpower and knowledge, our worker server has not been maintained for about 2 years. It cost me about 1 week just to understand what is going on.
The worker server have 2 main tasks to consider:
- RabbitMQ’s message management
- Elasticsearch’s index management
We will re-establish these tasks to batch server by:
- Database’s log tables management
- New OpenSearch’s index management
On log tables management, by using a log table instead of RabbitMQ, we need to build some features to manage how logs will be saved and read. For example, in case of scaling out the log tables, we should make a flexible feature that lets a writer easily write to the log meter table to target progressed log IDs and reference them with the log tables.
On the latter, because the maintenance effort won’t be too heavy, with the same effort, we could also build a flexible client that we can understand and control without worrying about compatibility issues. In other words, instead of using a pre-built sledgehammer API client library, a lightweight and controllable API client which created by our own hand seems more suitable.
At this time, by eliminate both RabbitMQ and Ruby Worker, our system are become more minimalist and easy to control.
Refactor legacy application code
Our main goal was to adapt the application code to all of the breaking changes. The document schema and all legacy application code became too rusty to adapt to the new OpenSearch version. There were many changes to survive, from new mapping fields, to changes in the search API and DSL that required rewriting most of our queries (we used filtered and missing queries a lot).
For responses received from OpenSearch, we could easily turn the returned result from an array to a DTO and do whatever we want without a second thought. But on the opposite, making a query for search request is unpredictable. Different requirements may require different queries. Fortunately, we could predict the structure of the query, and the fields, are already pre-schematised. So it’s easy to imagine that the work of choosing which fields are suitable for assembling a query could be related to crafting a set of legos.
For example:
class ShouldQuery
{
/** @var TitleJA|null */
public $title_ja = null;
/** @var CompanyCategories|null */
public $company_categories = null;
/**
* @return array
*/
public function build()
{
$result = [];
if (isset($this->title)) {
$result[] = $this->title->build();
}
...
if (isset($this->company_categories)) {
$result[] = $this->company_categories->build();
}
return $result;
}
}
class TextJA
{
/** @var string[] */
public $values;
/**
* @param string[] $values
*/
public function __construct($values)
{
$this->values = $values;
}
/**
* @return array
*/
public function build()
{
return ['terms' => ['text.ja' => $this->values]];
}
}Will generate this part of DSL query
{
...
"should": [
...
{
"terms": {
"title.ja": ["value"]
}
},
...
{
"terms": {
"company_categories": [3]
}
},
...
],
...
}If you want to know more about refactoring legacy code in PR TIMES. This is some interesting blog that you could take a visit:


Result
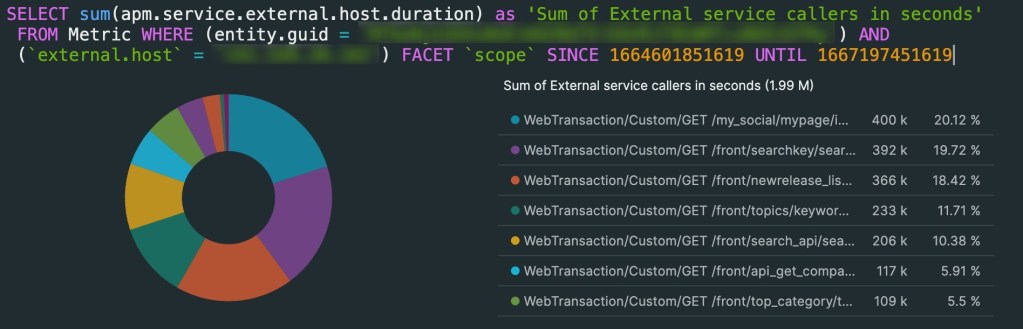
Used New Relic to monitoring our OpenSearch cluster through CloudWatch Metric Streams, over few weeks run time observation, we were able to confirm that the stability of the cluster had improved remarkably.

We measured 10% disk space are saved per index.
GET /_cat/indices/prtimes_current?v&h=index,pri.store.size
index pri.store.size
prtimes.20221130 37.2gb GET /_cat/indices/prtimes_current?v=true&h=index,pri.store.size
index pri.store.size
prtimes_20221130_165809 33.8gbAnd reduction of 40% response time.


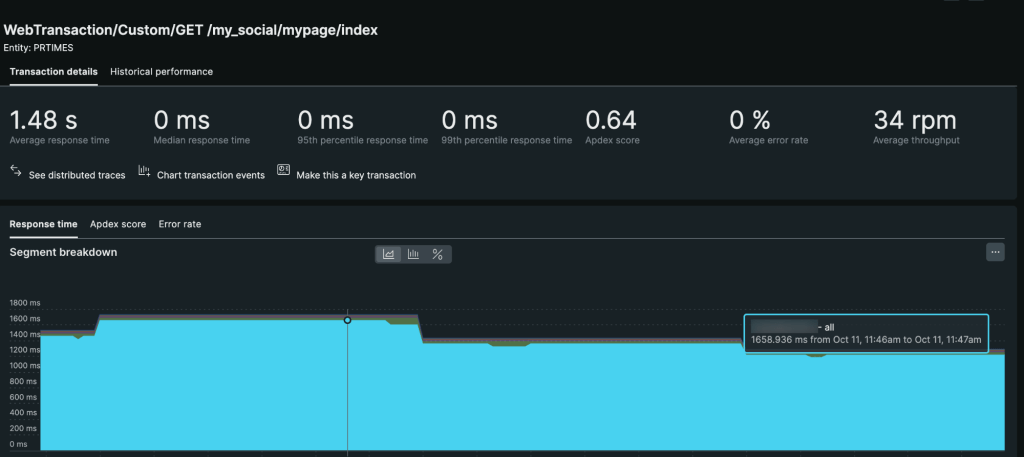

In the end, we successfully completed the upgrade and migration of data to our new OpenSearch with no downtime, resulting a cleaner and more streamlined architecture that eliminates the risk of data loss, and easier to understand and work with. Rebuild index everyday is no more needed, and even in case we need to rebuild, the rebuild time was also significantly reduced from more than 10 hours to 2-3 hours, gives us the ability to scale more efficiently, which will be vital as we continue to grow and expand.
The lasted OpenSearch version has also improved performance, resulting in a better user experience. From now interesting features like Index Sorting, SQL, Managing indexes could be used in our application.
By moved from self-managed implementation of Elasticsearch to managed Amazon OpenSearch Service, we were able to deploy, operate, and scale OpenSearch cluster easily, securely and cost-effectively in the AWS Cloud. This change allowed us to focus on our search application rather than worrying about maintaining and managing the underlying infrastructure. It is easy to set up, takes care of everything like configuration and maintenance, provides cross AZ availability backup, scaling takes only around 5-10 minutes without affecting the production. AWS OpenSearch Service also provided us a easy way to approach monitoring metrics like search rate, search latency, indexing rate, indexing latency, CPU, memory utilisation and even slow query logs.
Conclusion
It’s important to remember that upgrading data stores is not a sprint, but rather a marathon that requires careful planning and attention to detail. This is especially true when it comes to migrating data in a live production system, as any mistakes or oversights can have serious consequences.
It’s also a good idea to seek out resources and advice from others who have experience. By leveraging the knowledge and expertise of others, you can improve your chances of success and avoid making costly mistakes. Additionally, it’s important to prioritise regular testing and validation throughout the upgrade process, as this can help you identify and resolve any issues before they become major problems. By taking the time to carefully plan out every step of the process and staying focused, it’s possible to successfully complete the upgrade and ensure that your data is safe and secure.







