
こんにちは、普段PR TIMES STORY(以下STORY)の開発リーダーをしている岩下(@iwashi623)です。
今回はリリース当時からSTORYが抱えていた課題とそれを解消した方法について背景とともにお伝えできればと思います。途中、STORY独自の辛みや設計などが出てきて読みづらいとは思いますが、「へぇ〜そうなっていたんだ」のような温かい目線で楽しんで読んでいただけると幸いです😊
前提
STORYはローンチ以降、様々な課題を抱えてていましたが、それをお話するにはまず前提となる知識が必要です。まずはそちらを解説します。
以下は以前までのSTORYのアーキテクチャを簡単に表した図です。
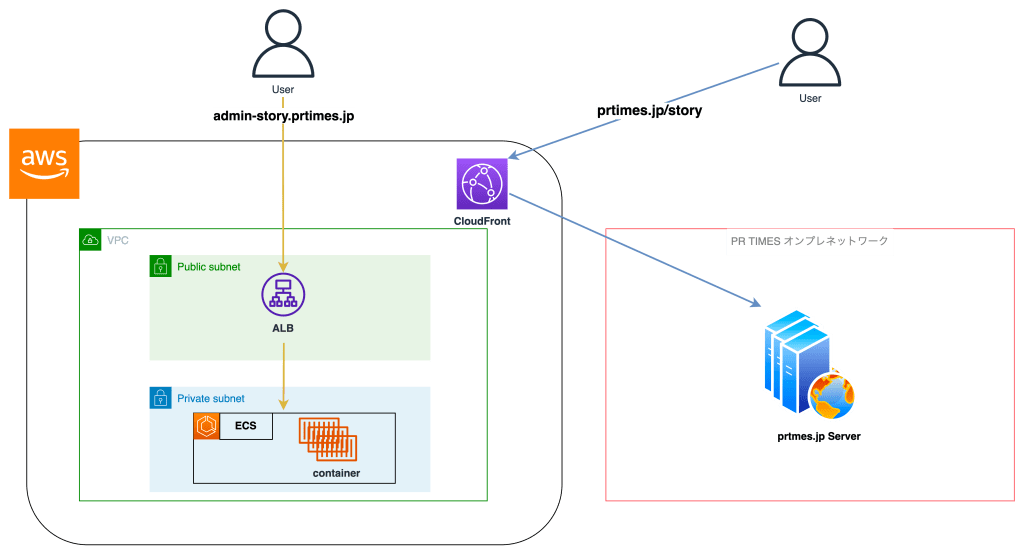
まず分かることは、prtimes.jpとadmin-story.prtimes.jpという2つのドメインがあることです。
prtimes.jpの方では/story以下のパスでSTORYの投稿が見れる画面(以下、投稿配信画面)がPR TIMESのオンプレサーバーで生成されて配信されています。また、途中リクエストがAWSのCDNであるCloudFrontを経由していることがわかります。
一方でadmin-story.prtimes.jpというドメインでは、リクエストが直接AWSのALBに飛んでいて、特にCDNなどは挟んでいません。AWS ALBのターゲットとなっているECSから画面が配信されており、こちらのECSには投稿配信画面以外すべてのアプリケーションのロジック(入稿画面やメール送信処理など)が含まれています。こちらのアプリケーションコードやインフラはPR TIMESのオンプレやPR TIMES(prtimes.jp)からは完全に独立していました。
アプリケーションコードベースでいうと、投稿配信側(prtimes.jp/story) は弊社サービスであるPR TIMES と同じリポジトリ・FWで管理されており、admin-story.prtimes.jpドメインのその他の機能は完全に別リポジトリ管理となっていてLaravelを使用しています。
このように、STORYはインフラ・アプリケーションコードの両面で投稿配信側とそれ以外で分割されており、これが原因で様々な問題が生じていました。
PR TIMES STORYが抱えていた課題
キャッチアップの難しさ
前述のアーキテクチャだと、STORYのチームのメンバーはAWSとオンプレの2種類のインフラを見る必要があります。また、アプリケーションも2つのリポジトリがあり片方が独自FW、片方がLaravelと違うFWを採用しているためコードを理解するのにも障害となっていました。
実際、新機能や改修を加えようとした際はまずどのコードがどこにあるかを探しにいくことが非常に多く、開発工数がかさんでいることが多かったです。また、新規にチームにアサインされた方はこちらのアーキテクチャとFWを頭に入れる必要があります。
この事象は手を動かすエンジニアだけの話ではなく、QAエンジニア、PdMなど新たにチームにJoinされた方に説明するのもなかなか骨の折れる作業でした。
新機能追加の際の工数増加
一つのアプリケーションを複数のリポジトリ・サーバーで運用すると、新規機能追加の際にサーバー間の通信を考慮する必要があります。
前述したようにSTORYでは投稿配信画面とその他の機能が別々のサーバーにデプロイされていました。また、投稿配信画面のあるオンプレのDBにはSTORYの投稿データなどは存在しません。STORYにまつわる大部分のデータはAWS VPC上のAuroraに入っています。オンプレサーバーはこのAuroraに直接接続はできず、その他の機能がデプロイされているECSがそのAuroraと接続できます。
そのため、ECSには投稿配信画面を表示するのに必要なデータをJson形式で返すAPIが複数設置されています。

赤い矢印で表した部分がprtimes.jpサーバーのアプリケーションとECSのアプリケーションの通信です。オンプレにあるアプリケーションから、ECS側に実装したAPIにHTTPリクエストが飛んでいます。
このような構成だと機能追加の際に新たなテーブルやカラムが増えると、ECS側のアプリケーションのAPIを追加・修正する必要があります。ただ、この構成自体は一般的にはそこまで問題ではありません。マイクロサービスアーキテクチャなどは実際にこういった構成でサーバー間が通信していると思います。ではなぜSTORYにおいては問題になるのでしょうか?
それはエンジニアリソースが限られている点です。マイクロサービスは基本的に、モノリシックなアーキテクチャだとデプロイや機能追加になんらかの障害をかかえたアプリケーションが取りうる手段の一つです。
一方でSTORYはまだまだ新規のサービスであり、社内のエンジニアリソースはとても限定的です。そのような状況でSTORYの中でアプリケーションを分割をしてもマイクロサービスの恩恵を受けられず、むしろAPIの設計・実装などを考える手間が増えているような状況でした。
耐障害性の問題点
STORYの中で多くユーザーに見られる画面はサービスのTop画面である投稿配信側の投稿一覧画面や投稿詳細画面です。こちらは前述の通りPR TIMESと同じサーバー、(コード上は)同じアプリケーションとなっています。ですので当然、PR TIMESが障害でダウンした際はSTORYの投稿配信画面も同時にダウンすることとなります。
PR TIMESのインフラ・アプリケーション起因で、別サービスであるSTORYが障害となる設計は問題があると感じていました。
異なるデプロイフロー
デプロイする目標が投稿配信画面(オンプレサーバー)とそれ以外の機能(ECS)で異なるため、デプロイフローもそれぞれに用意されていました。
オンプレ側はデプロイサーバーでデプロイスクリプトを実行するフローとなっています。
一方、以下はECSで使用しているデプロイフローです。GitHubのターゲットブランチへのマージをトリガーにCodePipelineが実行されるフローになっています。

デプロイの方法が異なるだけなら覚えるだけなのでそれほど問題にはなりません。ここで生じていた問題点は異なるアプリケーションデプロイスケジュールを抑える必要があることやQAの難しさです。
前述したようにこれまでの構成はエンジニアでもSTORYチームの人間しかほとんど把握しておらず、チームを横断して担当されているQAエンジニアの方や他のチームのエンジニアに理解を強いるのは酷なことでした。
実際に上記画像のようなやり取りが頻繁に行われていました。

これはQAエンジニアの方や他のチームのエンジニアの問題では決してなく、設計・構造上の問題です。STORYのチームが小規模なうちはもっとシンプルでわかりやすいインフラ設計が求められていました。
問題を解決するためにやったこと
PR TIMES STORYのアプリケーションを統合する
こちらは前述した【キャッチアップの難しさ】という課題に主に関係のある改修です。一つのリポジトリでアプリケーションが管理されるようになればSTORYチームのエンジニアは一つのFW(今回はLaravel)アプリケーションに集中できます。
実際に、独自FWに乗っているコードをLaravelへと移植する作業は割と大変でした。PHPのバージョンやテンプレートエンジン(PR TIMESはSmarty, STORYはLaravel標準のblade)の差異があるため、それぞれキャッチアップしつつ一つ一つ移植していきました。
特に(必要な場合を除いて)リファクタリングなどはせず、すでにあるLaravelアプリケーションのapp配下のController層やService層に新たにstoryというディレクトリを切って、その中で投稿配信側に関するロジックを押し込むことで工数を最小にしました。
root
└── app
├── controllers
│ ├── 既存ControllerディレクトリA
│ ├── 既存ControllerディレクトリB
│ ├── 既存ControllerディレクトリC
│ └── story ← 新規作成
│ └── 新規Controllerファイル ← 新規作成
└── services
├── 既存ServiceディレクトリA
├── 既存ServiceディレクトリB
├── 既存ServiceディレクトリC
└── story ← 新規作成
└── 新規Serviceファイル ← 新規作成こちらは一つ一つ移植して、Testを書いていく地味な作業でした。アプリケーションの既存コード理解につながったなと感じています。
インフラ構成を変更
もともと別々のサーバー、別ドメインで管理されていたアプリケーションを、統合して同じECSにデプロイするには、インフラの構成を変更する必要がありました。具体的に変更後のアーキテクチャは以下です。
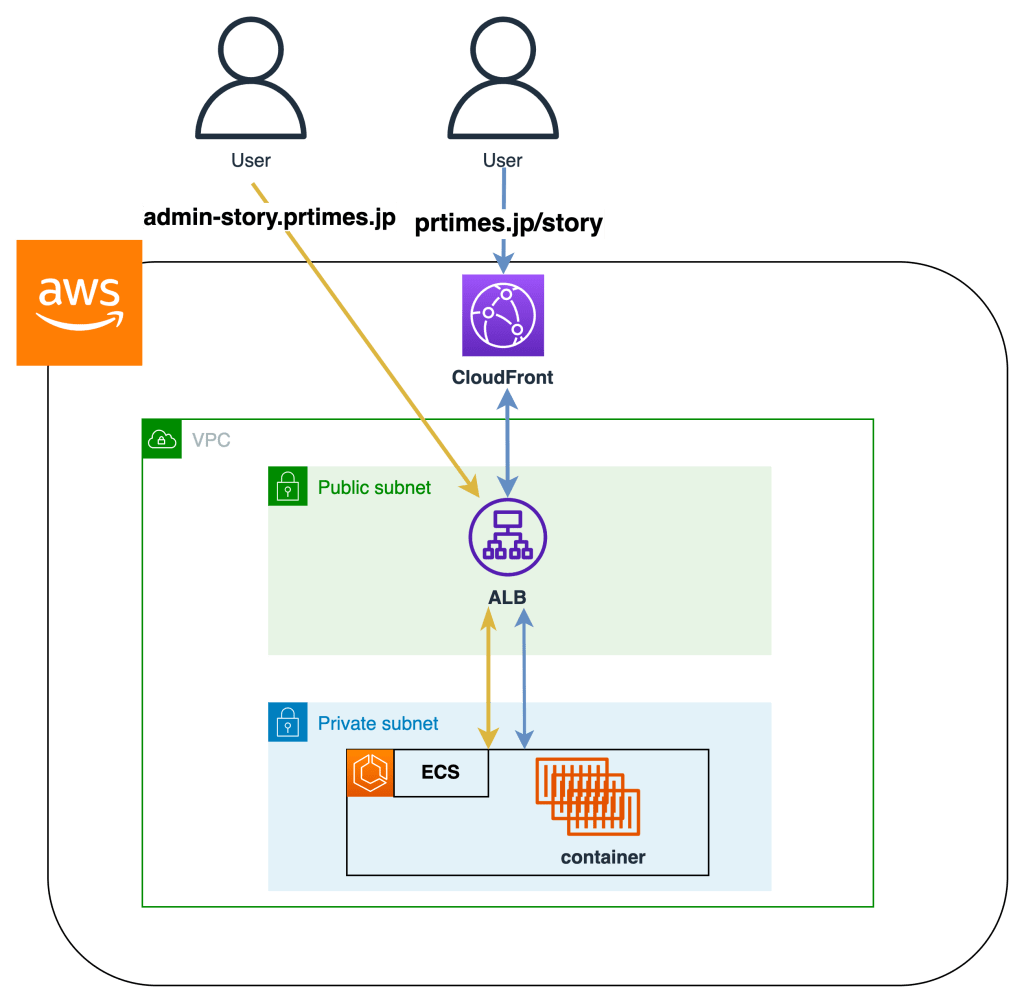
ドメインの数は変わっていません。以前と同じprtimes.jpとadmin-story.prtimes.jpが存在しています。変更されたのはprtimes.jpに/storyのパスでリクエストが来たときのCloudFrontのOriginです。
CloudFrontでは設定で振る舞い(ビヘイビア)を変えることができ、そのビヘイビアの設定の一つでPathごとにOriginを変更することができます。今回の場合ですと/storyと/story/*のパスへリクエストが来た際に、STORYで使用しているAWSのALBをOriginとするように設定しました。こうすることで今まで分割された異なるドメインのリクエストを同じALBに流すことが可能になります。
開発中のTips
1ページずつ移植する
いきなりCloudFrontのパスルーティングを使って/storyと/story/*のパスへリクエストが来た際に、STORYで使用しているAWSのALBをOriginとすると、STORYのすべてのページへのリクエストがALBやECSに流れ込むことになります。
すべてのページを一度にリリースすると、
- リリースのPull Requestが非常に大きくなりレビューが大変
- QA確認が非常に大変
- 不具合が起きたときに原因調査の対象のスコープが大きい
などの問題点があります。
そこで、今回は投稿配信側のページを1ページずつ移行していく方針を取りました。
具体的には、CloudFrontのビヘイビアに登録するパスを、まずはLPページ(/story/service)、次は投稿詳細ページ(/story/detail/*)、次は検索結果ページ(/story/search)…. などのように一つずつ追加していきました。STORYではリクエストのパスごとにどのコンテナがリクエストを捌くのかを設定するためにALBのパスルーティングも使用しているため、こちらにも同様に一つずつ移植対象のパスを追加していきます。
こうすることでリリースの粒度を小さくできます。
またその過程で気づいたのですが、ALBのリスナールールには一つのルールあたり最大5件までしか条件を追加できないようです。(制限緩和不可)
そのため、移植途中は以下のコードのようにTerrafromのコードがカオスなことになっていました😂
// STORYの配信画面
// リソース名がSTORYと不明瞭だが、移植する配信画面をアプリケーション側でstoryというNamespaceで管理しているためその名前を流用
// rule_1やrule_2のような数字は一時的にListener_ruleをたくさん作るための回避策(一つのルールに対しては5までしかConditionは指定できない)
resource "aws_lb_listener_rule" "story_path_rule_1" {
listener_arn = "省略"
priority = 20
condition {
path_pattern {
values = [
// "/story", // TODO: Topを移植したらコメントアウト解除
"/story/service",
"/story/service/",
"/story/ajax/media_login",
"/story/ajax/media_login/",
]
}
}
// 〜〜〜中略〜〜〜
}
resource "aws_lb_listener_rule" "story_path_rule_2" {
listener_arn = "省略"
priority = 21
condition {
path_pattern {
values = [
"/story/search",
"/story/ajax/story_search",
"/story/search/",
"/story/ajax/story_search/"
]
}
}
// 〜〜〜中略〜〜〜
}
resource "aws_lb_listener_rule" "story_path_rule_3" {
listener_arn = "省略"
priority = 22
condition {
path_pattern {
values = [
"/story/tag/*",
"/story/business_category/*",
"/story/ajax/story_index",
"/story/ajax/story_index/",
]
}
}
// 〜〜〜中略〜〜〜
}
resource "aws_lb_listener_rule" "story_path_rule_4" {
listener_arn = "省略"
priority = 23
condition {
path_pattern {
values = [
"/story/detail/*",
]
}
}
// 〜〜〜中略〜〜〜
}こちらで大量に生成されたリスナールールは、すべてのページを移植完了後にワイルドカードとして置き換えることで無事一つのルールにまとまりました。
Goals、Non-goalsを明確にする
本改修は移植対象となるコードが非常に多い改修でした。そのため着手前にDesign Docを書き、予め本改修のスコープをきっちりと線引しました。

具体的に定めたGoals, Non-goalsは以下です。
Gloals
- PR TIMESリポジトリで管理されているSTORY投稿配信機能のコードを、STORYリポジトリに移植する。
prtimes.jp/storyへのアクセスをSTORYサーバー(ECS)で捌けるようにCloudFront、ALBのルーティング変更・追加。
Non-gloals
admin-story.prtimes.jpドメインを廃止して、prtimes.jpドメインで配信するための変更は含まない。- 移植元のPR TIMESで管理されているコードのリファクタリング。
事前にDesign DocでGloals、Non-goalsを定めておくことで、やることが明確になりました。リファクタリングなどは移植しているときにやりたくなりがちですが、新種のバグが生まれる可能性もあります。まずは動く状態をリリース → リリース後に改善という流れでプロジェクトを進められたので、結果として移植にかかる時間の削減に繋がったかと思います。
まとめ
今回の改修は特に見た目などは変わらず、直接のビジネスインパクトなどはありません。ただ、間違いなくコード・インフラの両面がシンプルになりました。新規にJoinするエンジニアやメンバーはキャッチアップしやすくなり、PR TIMESへの依存もなくなりました。
こちらのタスクに2ヶ月近く一人のエンジニアのリソースを割いて意味があったのかは今後の機能追加にかかってくると思います。これからさらにスピードを上げて、PR TIMES STORYをよりよいサービスにしていけるようにがんばります💪
一緒にPR TIMES, PR TIMES STORYを盛り上げたい!と思っていただけた方は選考やカジュアル面談などに応募していただけると嬉しいです。








