
皆さんこんにちは!PR TIMESの開発部からのThaiです。
絶え間なく進化するテクノロジーの世界において、ソフトウェアプロジェクトの維持とアップグレードは、競争力と効果を確保するためには欠かせない要素です。最近、Webクリッピングのクローラープロジェクト「Puppeteer + Node.JS」をバージョンアップし、完成させるというエキサイティングな旅を経験しました。
Webクリッピングとは、さまざまなサイトから記事をクロールし、ユーザーが設定したキーワードが含まれる記事をクリップすることで、メディア露出の調査や分析を行うことができるWebアプリケーションです。

最新バージョンのPuppeteerとNode.jsを更新することから、品質を保証するための自動テストの設定に至るまで、その過程の一歩一歩は新たな発見でした。今回はそれを共有したいと思います。
以前の状況
改善を進める前に、私たちのクローラーはPuppeteer 14とNode.js 16を基盤に運用されていました。以前にはニーズを満たしていたものの、現在Puppeteer 14は非推奨となりました。

参考: https://www.npmjs.com/package/puppeteer/v/14.3.0
さらに、このバージョンでは標準ブラウザの使用時に問題が発生し、Chromiumを手動でインストールする必要がありました。これにより開発と保守のプロセスが複雑になっていました。
改善の流れ
Linterツール「xo」でコードを最適化
最初に、既存のコードをLinterを使用して改善することに集中しました。コード内の潜在的なエラーを検出し修正するのに役立ち、統一されたコードスタイルを維持することで、コードの標準を向上させます。この作業は、コードをより読みやすく保守しやすくするだけでなく、将来的な開発でのエラーのリスクを最小限に抑えることができます。
「ESLint」と「Prettier」は良い選択でしたが、xoのシンプルさと使いやすさを評価しましたので、xoを使いました。

xoはLinterとフォーマッタを一体化しており、設定がほぼ不要です。デフォルトで厳格なルールが適用され、追加のカスタマイズなしで高品質なコードを維持できます。加えて、xoは軽量でパフォーマンスが良く、他のツールに比べてセットアップも簡単です。Linterツールを導入することで、自分のコード内でいくつかの問題を発見し改善することができました。百聞は一見に如かず、本当に自分で試してみて、linterがシステムの品質とパフォーマンスを向上させる力を実感しました。
当社では、xoも他のフロントエンドプロジェクトのリンターとして使用されています。もしxoに興味がある方は、ぜひ以下のブログをご覧ください。

CIによるテストの統合
テストを作成
バージョンアップする際、システムが正しく動作し続けることを確認するのは大切です。そこで、テストを記述し維持することが非常に重要となります。バージョンアップの過程で、予期しない変更や衝突が発生することがあり、これによりシステムに潜在的なバグが生じる可能性があります。テストを行うことで、既存の機能が影響を受けず、新しい変更が問題を引き起こさないことを確認できます。
クローラーのテストに関する情報をGoogleで調べてみましたが、あまり多くの結果を見つけることができませんでした。どうやら、このテーマはまだネット上であまり一般的に取り上げられていないように感じました。そのため、クローラーのテストに使用できるツールについて、ChatGPTに相談してみました。
ChatGPTは、Mocha、Jest、Vitestなど、さまざまなテストライブラリを提案してくれました。それぞれのライブラリには独自の利点があり、どれを選ぶべきか悩みました。しばらく悩んだ末に、Mochaを選ぶことにしました。なぜなら、このライブラリは使いやすく感じたからです。さらに、MochaはPuppeteer自体でもテストを書くために使われています。
以下は mochaのインストールと使用方法です。
npm install --save-dev mocha @types/mocha/crawler ├── src │ ├── ... │ └── test │ ├── example.spec.ts <-- テストファイル │ └── ... │ ├── .mocharc.json <-- mochaの設定 └── ....mocharc.json
{
"require": [
"ts-node/register",
"tsconfig-paths/register"
],
"extension": ["ts"],
"spec": "src/test/**/*.spec.ts",
}この設定ファイルの各オプションは次のような意味を持つ
- require
"ts-node/register": これは、Mochaがテストを実行するときに、TypeScriptファイルを直接実行できるように ts-node を登録している。これにより、TypeScriptで書かれたテストをJavaScriptにトランスパイルせずに実行できる"tsconfig-paths/register": これは、TypeScriptの paths や baseUrl の設定を解決するために使用する。主にtsconfig.jsonに定義されたパスエイリアスを解決するために使われる
- extension
["ts"]: Mochaが認識し、テストファイルとして扱うファイルの拡張子を指定している。TypeScriptでテストを書くので、 .ts に設定する
- spec
"src/test/**/*.spec.ts": テストファイルのパターンを指定している。ここでは、src/testディレクトリ内のすべてのサブディレクトリを含む、.spec.tsで終わるファイルが対象となる
[例] test ディレクトリに detail.spec.tsファイルを作成し、以下のテストコードを追加する
import {DetailCrawler} from '@crawler';
import Logger from '@logger';
import {assert} from 'chai';
import {before, after} from 'mocha';
import {type DetailSetting} from '@types';
import {CrawlerTime} from '@enums';
describe('Detail Crawler', () => {
const logger = new Logger('test');
const crawler = new DetailCrawler(logger);
const ssrPage = 'http://localhost:3000/ssr/article'; // テスト用のクローラサイト
before(async () => {
await crawler.init();
await crawler.gotoURL(ssrPage);
});
after(async () => {
await crawler.close();
});
it(`get title correctly`, async () => {
const actualTitle = await crawler.getTitle('#title');
const expectedTitle = 'SSR Article Title';
assert.equal(actualTitle, expectedTitle);
});
it(`get content correctly`, async () => {
const actualContent = await crawler.getContent('#content');
const expectedContent = 'SSR Article Content Sub Content ';
assert.equal(actualContent, expectedContent);
});
...
});テストを書いた後、実行できるようにpackage.json を開き、スクリプトを追加する
{
"name": "crawler",
"version": "1.0.0",
"description": "Clipping crawler",
"scripts": {
...
"test": "mocha", <-- テストを実行するスクリプト
},
...
}テストするために、以下のコマンドを実行する
npm run test
CI環境に自動テストを導入
GitHub Actionsを利用し、継続的インテグレーション環境において自動テストを組み込みました。
name: Test Crawler
on:
push:
jobs:
test-crawler:
runs-on: ubuntu-latest
defaults:
run:
working-directory: ./crawler
steps:
- name: Checkout Repo
uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version-file: crawler/.nvmrc
- name: Install Crawler Dependencies
run: npm ci
- name: Run Linter Check
run: npm run lint
- name: Run Code Build Check
run: npm run build
- name: Run Test Crawler
run: npm run test:ci
Node.JSをバージョンアップ
Puppeteerの最新バージョンを使いたいです。しかし、Puppeteerのリリースノートによると、バージョン22以降はNode.js 16のサポートが終了しています。そのため、Puppeteerの最新バージョンを使用するために、まずNode.jsをバージョンアップする必要があります。

安全のため、新しいバージョンに移行した際に、何らかのトラブルが発生するなら、すぐに元のバージョンへと戻せる柔軟な対応ができる方法を探していました。「nvm(Node Version Manager)」を選びました。
nvmを使うと、複数のNode.jsバージョンを簡単に管理でき、特定のバージョンを瞬時に切り替えたり、元のバージョンに戻したりすることができます。これにより、リスクを最小限に抑えながら新しいバージョンに挑戦できるのです。Node.jsを使っている方には、ぜひnvmを試してみることをおすすめします。
nvmのインストール自体は非常にシンプルです。公式のドキュメントを参考にすれば、手順に従って簡単にセットアップすることができます。詳しい手順や設定については、上のリンクからnvmの公式リポジトリをご覧ください。
Webクリッピングは複数のEC2インスタンスにnvmとNode.jsをインストールする必要があります。手動で各サーバーに一つずつインストールしていくのは非常に手間がかかり、効率が悪いと感じました。さらに、手動での作業では、すべてのサーバーに対して100%同じ設定が行われているかどうか確認するのが難しく、インストール中にミスが発生する可能性もあります。
このような問題を避けるために、Ansibleを使って作業を自動化することにしました。Ansibleを使えば、一度Playbookを作成すれば、その手順を何度も繰り返し実行でき、全てのサーバーに対して同じ環境を正確に適用することができます。これにより、作業時間を大幅に短縮でき、ヒューマンエラーのリスクも減少します。
以下は、nvmとNode.jsのインストールを自動化するために私が作成したAnsibleのPlaybookです。
---
- name: Install nvm
ansible.builtin.shell: >
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.1/install.sh | bash
args:
creates: "{{ ansible_env.HOME }}/.nvm/nvm.sh"
- name: Install Node.js by nvm
ansible.builtin.shell: >
. {{ ansible_env.HOME }}/.nvm/nvm.sh && nvm install {{ nvm.node.version }}
args:
creates: "{{ ansible_env.HOME }}/.nvm/versions/node/v{{ nvm.node.version }}"
register: node_install
failed_when: node_install.rc != 0
# Set the newly installed Node.js version as default
- name: Create default version alias file for nvm
become: yes
file:
path: "{{ ansible_env.HOME }}/.nvm/alias/default"
state: touch
- name: Write the default Node.js version into alias file
become: yes
copy:
content: "{{ nvm.node.version }}\n"
dest: "{{ ansible_env.HOME }}/.nvm/alias/default"
# Create symbolic link in the /usr/local/bin directory to use the latest version of Node.js across all user accounts (ec2-user, apache, etc...)
- name: Create symbolic link for node
become: yes
ansible.builtin.file:
src: "{{ ansible_env.HOME }}/.nvm/versions/node/v{{ nvm.node.version }}/bin/node"
dest: "/usr/local/bin/node"
state: link
force: yes
- name: Create symbolic link for npm
become: yes
ansible.builtin.file:
src: "{{ ansible_env.HOME }}/.nvm/versions/node/v{{ nvm.node.version }}/bin/npm"
dest: "/usr/local/bin/npm"
state: link
force: yesもしNode.jsの他のバージョンに切り替えたい場合は、Ansible Playbook内のnvm.node.versionの値を変更するだけで、全てのサーバーに対して一斉にバージョンを変更することができます。Playbookを再実行するだけで、全てのサーバーが同じバージョンに統一されるため、手動で行う場合に比べてミスが発生するリスクもなくなります。
これが自動化の素晴らしいところで、特に大規模な環境では、手動でインストールや変更作業を行う煩わしさやミスを防ぐことができるのです。本当に便利ですよね!
Puppeteerをバージョンアップ
最後はPuppeteerとその関連パッケージのバージョンアップです。この作業で最も時間を要するのは、新しいバージョンに対してクローラーが正常に動作するかどうかの確認です。やっぱりPuppeteerのバージョンをアップしてテストを再実行したところ、いくつかのエラーが発生しました。
- Could not find expected browser locally
- Property ‘waitForTimeout’ does not exist on type ‘Page’
- Error: Failed to launch the browser process! chrome_crashpad_handler: –database is required
- Headless mode
それぞれの問題に対してどのように対応したかを詳しく説明します。
Could not find expected browser locally
Puppeteerのv19.0.0以降、ブラウザはデフォルトで~/.cache/puppeteerディレクトリに保存されます。
Puppeteerのドキュメントによれば、この設定は、Puppeteerがいくつかのビルドステップでパッケージ化され、新しい場所に移動された場合に問題を引き起こす可能性があります。特に、Webクリッピングの場合はシンボリックリンクを使用しており、この状況が発生しました。Webクリッピングのコードをデプロイする際には、ec2-userユーザーでサーバーにデプロイします。そのため、Puppeteerは自動的にブラウザを~/.cache/puppeteerディレクトリ、つまり/home/ec2-user/.cache/puppeteerにダウンロードしました。
しかし、別のユーザー(たとえばapache)がアプリケーションを実行すると、以下のエラーが発生してしまいました。
...
your cache path is incorrectly configured
(which is: /usr/share/httpd/.cache/puppeteer)
check out our guide on configuring puppeteer at https://pptr.dev/guides/configuration
...このエラーを見ると、apacheユーザーで実行する場合、Puppeteerは異なるディレクトリ、具体的には/usr/share/httpd/.cache/puppeteerにブラウザを探したとわかりまた。そのため、ここにはブラウザがインストールされておらず、Puppeteerはブラウザを起動できません。
Puppeteerのドキュメントを参照したところ、ブラウザを保存するパスの値(executablePath)は、Puppeteerが自動的に計算して、ブラウザを検索および起動する際に使用することがわかりました。おそらくこの理由から、ユーザーによってブラウザのパスが違うと思われます。
参考: https://pptr.dev/api/puppeteer.configuration
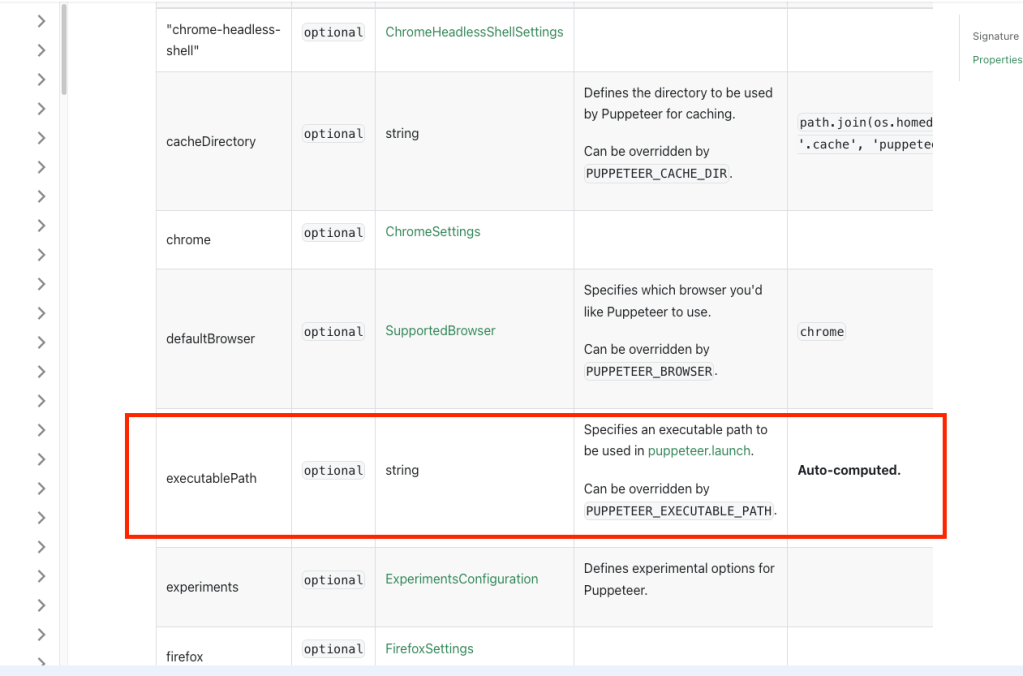
この問題を解決するために、デフォルト設定を使用する代わりにPuppeteerのドキュメントを参考して以下のように設定しました。
.puppeteerrc.cjs を作って、ブラウザを保存する位置を手動で指定しました。
/crawler
├── src
│ ├── ...
├── .puppeteerrc.cjs <-- 設定ファイル
└── ...const {join} = require('path');
/**
* @type {import("puppeteer").Configuration}
*/
module.exports = {
// Starting in v19.0.0, Puppeteer stores browsers in ~/.cache/puppeteer to globally cache browsers between installation.
// This can cause problems if puppeteer is packed during some build step and moved to a fresh location.
// The following configuration can solve this issue
// https://pptr.dev/guides/configuration#changing-the-default-cache-directory
cacheDirectory: join(__dirname, '.cache', 'puppeteer'),
};Property ‘waitForTimeout’ does not exist on type ‘Page’
Puppeteer v22.0.0からwaitForTimeoutがremoveされました。

Puppeteerの開発者たちは、waitForTimeoutを使用する代わりにwaitForSelectorやwaitForなどの代替案を提案していますが、現時点での技術的要件から、すぐにこの関数の使用を中止することはできません。システムの現行仕様を変えずにwaitForTimeout関数の代替策を見つける必要があります。幸運なことに、Puppeteer v22のリリースノートのコメントセクションで、開発者の一人であるOrKoNさんが代替策を提供しています。

参考: https://github.com/puppeteer/puppeteer/pull/11780#issuecomment-1975869042
その方法は、node:timers/promisesのsetTimeout関数を利用することです。
# before
await page.waitForTimeout(1000);
# after
import {setTimeout} from 'node:timers/promises';
...
await setTimeout(1000);Error: Failed to launch the browser process! chrome_crashpad_handler: –database is required
このエラーを見たとき、初めてのもので驚きました。インターネットで調べたところ、以下の関連するIssueを見つけました。
Puppeteerの主要開発者の一人が、Puppeteerの設定ファイルの保存場所を明示的に指定するという解決策を提案していました。

その方法を試してみたところ、エラーは消えました。🚀
crawler/.env
XDG_CONFIG_HOME=/tmp/.chromium
XDG_CACHE_HOME=/tmp/.chromiumHeadless mode | Puppeteerのデフォルトのヘッドレスモードにおける重要な変更
以前のバージョンからの問題を修正後、ローカル環境とステージング環境でのテストはすべて100%passしました。本番環境へ展開した際にも、クローラーは滞りなく動作しました。しかし、一日経たずして、MackerelからCPU使用率が高いと通知が届くようになりました。
これがPuppeteerのバージョンアップ直後に発生したため、何らかの変更がパフォーマンスに影響を与えているのではと考えました。
インターネットで調べてみて、Puppeteerのバージョン22以降では大きな変更があるとわかりました。
Before v22, Puppeteer launched the old Headless mode by default. The old headless mode is now known as chrome-headless-shell and ships as a separate binary. chrome-headless-shell does not match the behavior of the regular Chrome completely but it is currently more performant for automation tasks where the complete Chrome feature set is not needed.
v22以前では、Puppeteerは古いヘッドレスモードをデフォルトで起動していました。古いヘッドレスモードは現在chrome-headless-shellとして知られ、別のバイナリとして出荷されています。chrome-headless-shellは通常のChromeの動作と完全に一致するわけではありませんが、完全なChrome機能セットが必要ない自動化タスクでは、現在のところよりパフォーマンスが高くなっています。
https://pptr.dev/guides/headless-modes
Puppeteerのバージョン22以降はデフォルトで新しいHeadless mode(ヘッドレスモード)を使用します。
const browser = await puppeteer.launch();パフォーマンステストを行った結果、新しいヘッドレスモードは「chrome-headless-shell」と呼ばれる旧ヘッドレスモードよりもCPUの使用量が多いことが判明しました。
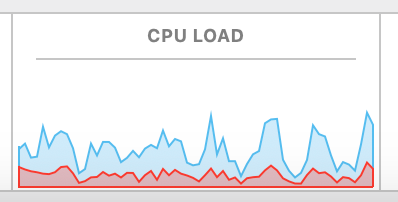

これにより、システムリソースが限られているアプリケーションを運用している場合、新しいヘッドレスモードの使用はパフォーマンスの問題を引き起こす可能性があります。
以下の図を見ると、旧ヘッドレスモードは軽量で、パフォーマンスが優れており、クローリングやウェブスクレイピングなどのタスクに適していることがわかります。

参考:https://developer.chrome.com/blog/chrome-headless-shell
そのため、旧ヘッドレスモードを利用するように修正し直しました。
const browser = await puppeteer.launch({headless: 'shell'});その結果は本番環境にデプロイした後、CPU使用率に関する警告が現れなくなったことを確認しました

感想
このバージョンアップの完了は、私にとって記念すべき一歩となりました。今後も引き続きシステムを観察し、パフォーマンスの最適化に努めていきます。私の経験が、同様の課題に直面している皆さんの参考になれば幸いです。ご覧いただき、ありがとうございました!🙇







