
こんにちは、21新卒の岩下です。
今回は私が普段開発を担当しているPR TIMES STORYのDBデータをBigQueryへ転送したので、そちらについての話を書いていきたいと思います!
はじめに
PR TIMES STORY(以下、STORY) では、データベースにMySQL互換のAmazon Auroraを使用しています。
本記事の目標はAuroraに蓄積されているデータをBigQueryへ転送して、データ分析に使用できる状態にすることです。その過程で、AWS Glueを使ったETL処理や、RDSのシステムスナップショットなど色々と学ぶことがありました。
やりたいこと
- 単純にいまDBに保存されているデータを全てBigQueryに転送するだけでは、プライバシーの観点から転送してはまずいデータなどが入り込んでしまいます。そのため、そういったカラムにはAWSのGlue といったETL処理ができるサービスなどでデータのマスキング処理を行う必要があります。
- ビジネス職の方でも必要な方が気軽に最新情報にアクセスするために、データ転送は自動で定期的に行われているのが好ましいです。
設計
今回最終的に使用したAWSリソースの構成は以下のようなものです。

Auroraのデータを定期的にマスキング処理を行って、BigQueryで読み込めるファイル形式で出力するために今回はGlueを採用しました。Glueを採用するメリットとしては、
- サーバーを意識することなくETL処理を行えるフルマネージドサービスであること
- Lambdaとは異なり、タイムアウトまでの時間が48時間あるため処理時間の長いワークロードにも対応可能なこと
- コンソール画面からやりたい処理を選択するだけで、ある程度ETLのためのコードを自動で生成してくれること
等が挙げれます。
Glueのデータ読み込み
Glueとデータソースの接続
STORYではなく、PR TIMESのデータをBigQueryに転送する対応をした模様が以前の開発者ブログで公開されています。

こちらの記事では、PostgreSQL on EC2のDBのデータをGlueとJDBC経由で接続して取得してETLロジックを書くことにより実現しています。今回も最初はこちらの記事を参考に、本番環境のリードレプリカへJDBC経由で接続して開発してみました。

- 転送するのは公開済みの記事情報のみで、未公開情報は転送しない。
- プライバシーに問題があるカラムはマスキングしてから転送する。
という要件を満たすためのETL処理を実際に開発も完了して、初日のデータ転送は成功。無事ETL処理の中のマスキング処理もされており、タスク完了!!!!
…と言いたいところでしたが、3日後くらいにデータを確認してみると本来取得したかったデータが欠けていることがわかりました。
なにを間違えたのか?
データがすべて転送されていなわけではないことや、Jobの実行履歴やログを見るにどこかでエラーが起きたわけではなさそうです。色々と調べていくと、Jobのブックマークという機能を有効にしていたことが原因のようです。
Jobのブックマークはデフォルトでは最後に読み込んだテーブルのプライマリーキーをチェックポイントとして保持しておき、次の実行以降では最後のチェックポイント以降のデータのみJobの対象として読み込みます。わかりやすくクエリで乱暴に表現すると以下のような感じでしょうか。
SELECT * FROM tables WHERE primary_key > 先日のチェックポイントSTORYは、サービスの性質上1日の間に記事が下書き作成〜公開状態になることは少なく、作成されてから何日も欠けて公開状態になるレコードがたくさんあります。つまり、Jobのブックマークを有効にしてしまうと公開されていない状態の時にETL処理の中に入って以降、次の実行からはETLの処理にすら入らないということになります。
変更のあるレコードを扱うために
上記のような性質のあるサービスで、それでも変更のあるテーブルをBigQueryで使いたい!という要望はどのように解決すれば良いでしょうか?ものすごくシンプルな策として、Jobのブックマークを解除して、常にレコードをフルスキャンする方法があるかと思います。フルスキャンした結果をGlueのETL処理にかければ、常に最新のDB状態に対してETL処理を実行したのと同義なのでほしい結果は割と簡単に手に入ります。
ただし、JDBC経由でデータを取得するときは注意が必要です。JDBC経由でデータを取得する際は、データソースのDBインスタンスのリソース(CPUやメモリなど)を使用しているため、データが大量にあるテーブルを扱うとDBに思いがけない負荷がかかる可能性があります。
スナップスナップショットとStart Export Task
実際は、現在のSTORYにはそこまでの大量のデータ量はないためアクセスの少ない時間帯(深夜など)にJobを実行すれば、接続先が本番環境のリードレプリカであっても負荷は大きな問題ではありませんでした。

そのため、「一旦、問題になるまでは現状の構成でブックマークを外せばいいかな」とも考えていました。ところが、色々と調査をするうちにAuroraには自動スナップショットとStart Export Taskという便利そうな機能があることに気づきました。
Start Export Taskは、DBのスナップショットをS3へバックグラウンドで転送してくれます。転送されたデータはKMSで暗号化されたparquet形式で出力されるようです。このファイルを使うことができれば、アクセスの少ない時間帯での負荷だけでなく、日中の開発エンドポイントを使用したETL処理の開発やJobの試験的な実行でも本番DBへの負荷を気にせず行えるようになると感じました。そのため少ない工数でその環境を開発できるのであれば、Glue JobのデータソースをAuroraからS3切り替えようと考えました。
Start Export Taskの自動実行
残念ながら、Start Export Taskの自動実行の設定は現在AWSのマネージメントコンソール上から行うことはできません。そのため、自動的にRDS APIの呼び出しまたはAWS CLIのコマンド実行をする仕組みが必要になります。
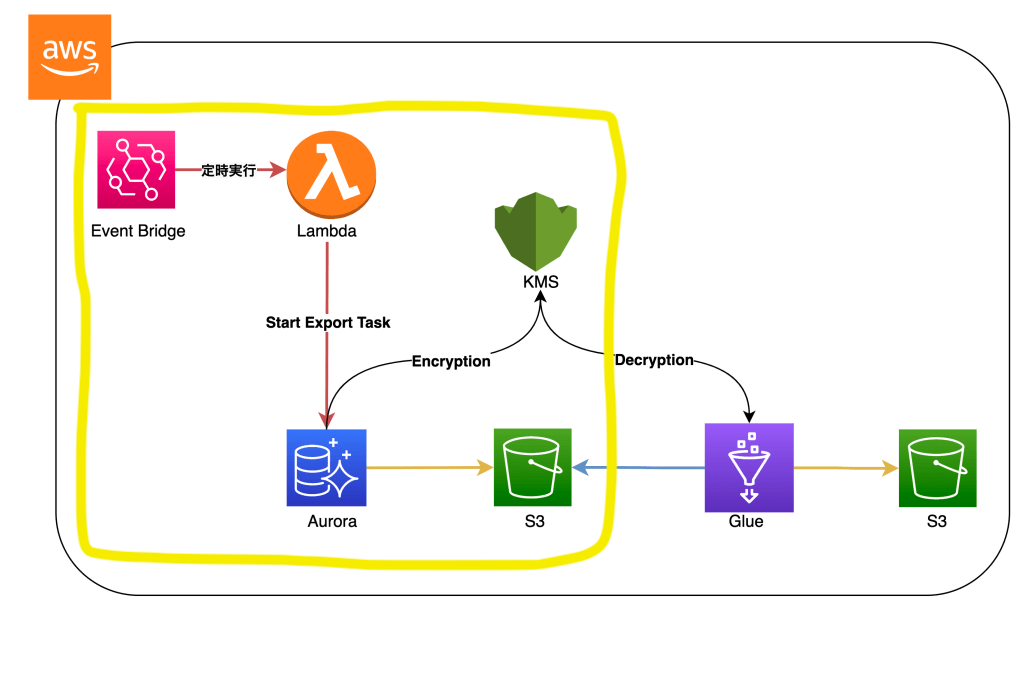
今回作成したスナップショットをS3に転送するための構成は画像の囲った部分です。LambdaではAWS SDKを使用してRDS APIを叩く仕組みをGoで実装しました。
こちらのLambdaアプリケーションをEvent Bridgeを使って定時実行することで自動的なSnapshotの転送を実現しています。
Start Export Taskを実行するGoのコードの中ではデータの暗号化のためのKMS KEY IDやスナップスナップを一意に絞り込むための識別子などを記述します。
Lambda実行時の注意点としては、KMSキーのキーユーザーとしてLambdaの実行ロールを登録しておかなければいけません。こちらの作業をしていないと、
ERROR: KMSKeyNotAccessibleFault: The KMS key <KEY_ID> doesn't exist or is disabled.というエラーがLambda実行時に発生します。KMSのキーを使えませんでしたというエラーですね。
手順としてはこちらの記事を参考にすると全体の流れとコードのイメージがつくかと思います。

S3のファイルをGlue読み込む
ここまでくれば、あとはGlue JobのデータソースをS3へ切り替えるだけです。実際に以下のようなコードでSnapshotの読み込みが行えました。
~~~省略~~~
# 読み込むS3のパス
readPath = "s3://BucketName/path/"
snapshotDynamicFrame = glueContext.create_dynamic_frame_from_options(
connection_type = "s3",
connection_options = {"paths": [readPath]},
format="parquet"
)またSnapshotのデータはKMSキーで暗号化されているため、Glueの実行ロールにKMSのDecryptionを許可するポリシーをアタッチする必要があります。
{
"Version": "2012-10-17"
"Statement": [
{
"Sid": "kmsDecriptPolicy",
"Action": [
"kms:Decrypt",
"kms:ReEncrypt*",
"kms:GenerateDataKey*",
"kms:DescribeKey"
],
"Effect": "Allow",
"Resource": "<対象キーのARN>"
}
],
}
Glueの機能である開発エンドポイントとnotebookを使用することで、デバッグしながら開発をすすめることができます。ただし料金はお高いので立ち上げっぱなしには注意が必要です。
Glueは実行時間あたりで課金されていく料金体系で、1DPU(Data Processing Unit)あたり$0.44/hour のお金がかかります。デフォルトでは開発エンドポイントには5DPUが割り振られていますので、一日つけっぱなしにしたときの料金を求める式は
$0.44 * 5DPU * 24時間です。こちらを計算すると52.8ドル となります。2022年2月25日現在の為替レートでは1ドル=115円なので6072円が一日で課金されることになります。使わなくなった開発エンドポイントは間違いなく消しましょう。
参考記事


BigQueryで簡単にクエリを実行するために
これまでの手順を実装すると、ETL処理で毎回データをフルスキャンしてもDBへの負荷を全く考慮に入れずにGlue Jobを実行できる環境を手に入れることができました。あとはDWH(弊社の場合はBigQuery)で更新のあったレコードをどのように扱うかを考えれば良いだけです。
パッと思いついたのは以下の2案でした。
- 公開済み記事かつ前回のJob実行から更新のあったレコード(updated_atが前回のJob実行よりあと)のみを転送する。ETL処理中に
transformed_atなどのカラムをレコードに追加しておき、BigQueryでクエリを叩く際にPrimary Keyが重複しているレコードが存在する場合はtransformed_atが最も新しいものを取得するようする。 - 常にすべての公開済み記事レコードを転送する。BigQuery側で、
transformed_atを元にパーティション分割をする。BigQueryにはクエリを叩く際にパーティション選択を強制する設定があるので、その設定を有効にして最新のパーティションからデータを取得する。
1のメリットとしてはETL後のデータ量が少なくなることが挙げられます。S3やBigQueryのストレージ料金もただではないですし、データ転送にかかる時間的コストも削減できます。ただし、BigQuery側で使用するクエリは複雑になりそうです。
2のメリットはシンプルさです。すべての公開済み記事データを毎回送信しているので発行するクエリもWHERE句を一つ書き足せば済みます。また、前回実行時間などを意識しなくて良いのでJobが失敗したときのデバッグや再実行が簡単です。
STORYでは今回2を選択しました。理由としてはデータ量が多くないためストレージ料金や転送時間が問題にならないことや、ビジネス職の方でも気軽にクエリを叩けるようにしたかったことが挙げられます。
transformed_at はGlueのETL処理の中で、DataFrameのwithColumnメソッドを使ってレコードにつけることにしました。
today = datetime.now()
currentRunTimestamp = today.astimezone(timezone('Asia/Tokyo')).strftime("%Y-%m-%d %H:%M:%S")
# transformed_atをカラムとして追加する関数
def addTransformedAt(glueContext, df) -> DynamicFrame:
dataframe = df.toDF()
df_with_transformed_at = dataframe.withColumn("transformed_at", lit(currentRunTimestamp))
return DynamicFrame.fromDF(df_with_transformed_at, glueContext)
# カラム追加
# snapshotDynamicFrameのところには任意のDynamicFrameが入った変数に置き換えてください
result = addTransformedAt(glueContext, snapshotDynamicFrame)データの削除
また、データ量が少ないのでストレージ料金が気にならないと言っても古いデータは不要であることは間違いないのです。そこでS3のデータに関してはオブジェクトのライフサイクルポリシーを、BigQueryのテーブルにはパーティションの有効期限を設定しました。BigQueryのパーティションの有効期限はコンソール上からは設定できないため、bqコマンドを実行する必要があります。

## dataset_name.table_nameのところは、データセットの名前とテーブルの名前に置き換えます。
bq update --time_partitioning_expiration 604800 dataset_name.table_nameちなみに
今回STORYのためには採用しなかったですが、1の方法は以下のようなPythonのコードでも実現できそうです。
import boto3
# Glueの実行日時を取得
client = boto3.client('glue', 'ap-northeast-1')
response = client.get_job_runs(
JobName='<実行履歴を検索するJobの名前>'
)
job_runs = response['JobRuns']
job_runs = sorted(job_runs, key=lambda i: i['StartedOn'], reverse=True)
# 前回実行開始時間を取得, あらかじめ決めた時間をハードコーディングしても良いかもしれません
lastRunDate = job_runs[1]['StartedOn'].strftime("%Y-%m-%d %H:%M:%S")
def sparkSqlQuery(glueContext, query, mapping) -> DynamicFrame:
for alias, frame in mapping.items():
frame.toDF().createOrReplaceTempView(alias)
result = spark.sql(query)
return DynamicFrame.fromDF(result, glueContext)
query = """
select * from myDataSource
where updated_at > '%s'
"""
# ※dynamicFrameNameはspark.sqlをかけたいdynamicframeに置き換え
result = sparkSqlQuery(
glueContext,
query=query %lastRunDate,
mapping={"myDataSource": dynamicFrameName},
)これから
今回初めてETL処理やそれに伴う技術について学びました。GlueやEvent Bridgeなど初めて触るマネージドサービスが多く、かなり勉強になることが多かったです。他の分野のAWSサービスよりも、学習コスト高いな〜というのが率直な感想です。
積み残している課題としては、Glueのパフォーマンス周りがあります。現状Glueの多くの設定をデフォルトの設定で使用しているため、STORYのデータに使用するにはオーバースペックなところがあるかなと思っています。Glueのパフォーマンス改善には以下のような記事が参考になりそうだと感じました。
- https://d1.awsstatic.com/webinars/jp/pdf/services/202108_Blackbelt_glue_etl_performance1.pdf
- https://buildersbox.corp-sansan.com/entry/2021/02/04/110000
パフォーマンスやコスト最適化をしっかりと考えて実装できるエンジニアになれるように、しっかりと計測と改善を繰り返していきたいと思います。







